AI Papers
Browse and discover the latest research papers on artificial intelligence, machine learning, and related fields.
💬
Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models
Sander Land, Max Bartolo
182
0
The disconnect between tokenizer creation and model training in language models has been known to allow for certain inputs, such as the infamous SolidGoldMagikarp token, to induce unwanted behaviour. Although such `glitch tokens' that are present in the tokenizer vocabulary, but are nearly or fully absent in training, have been observed across a variety of different models, a consistent way of identifying them has been missing. We present a comprehensive analysis of Large Language Model (LLM) tokenizers, specifically targeting this issue of detecting untrained and under-trained tokens. Through a combination of tokenizer analysis, model weight-based indicators, and prompting techniques, we develop effective methods for automatically detecting these problematic tokens. Our findings demonstrate the prevalence of such tokens across various models and provide insights into improving the efficiency and safety of language models.
5/10/2024
🖼️
Generative Multimodal Models are In-Context Learners
Quan Sun, Yufeng Cui, Xiaosong Zhang, Fan Zhang, Qiying Yu, Zhengxiong Luo, Yueze Wang, Yongming Rao, Jingjing Liu, Tiejun Huang, Xinlong Wang
153
0
The human ability to easily solve multimodal tasks in context (i.e., with only a few demonstrations or simple instructions), is what current multimodal systems have largely struggled to imitate. In this work, we demonstrate that the task-agnostic in-context learning capabilities of large multimodal models can be significantly enhanced by effective scaling-up. We introduce Emu2, a generative multimodal model with 37 billion parameters, trained on large-scale multimodal sequences with a unified autoregressive objective. Emu2 exhibits strong multimodal in-context learning abilities, even emerging to solve tasks that require on-the-fly reasoning, such as visual prompting and object-grounded generation. The model sets a new record on multiple multimodal understanding tasks in few-shot settings. When instruction-tuned to follow specific instructions, Emu2 further achieves new state-of-the-art on challenging tasks such as question answering benchmarks for large multimodal models and open-ended subject-driven generation. These achievements demonstrate that Emu2 can serve as a base model and general-purpose interface for a wide range of multimodal tasks. Code and models are publicly available to facilitate future research.
5/9/2024
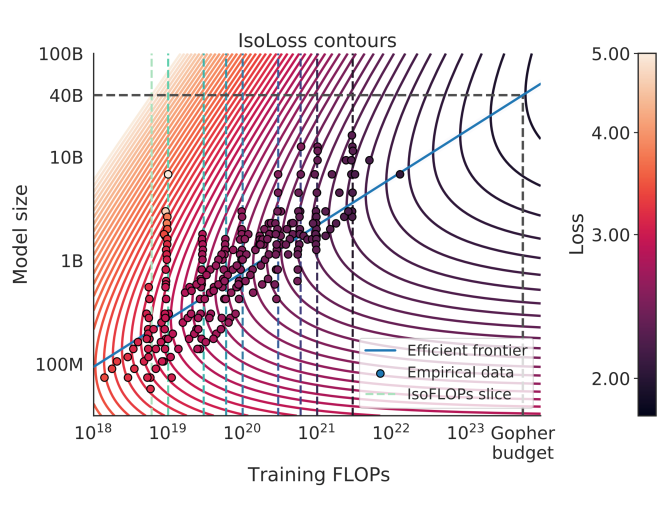
Chinchilla Scaling: A replication attempt
Tamay Besiroglu, Ege Erdil, Matthew Barnett, Josh You
124
0
Hoffmann et al. (2022) propose three methods for estimating a compute-optimal scaling law. We attempt to replicate their third estimation procedure, which involves fitting a parametric loss function to a reconstruction of data from their plots. We find that the reported estimates are inconsistent with their first two estimation methods, fail at fitting the extracted data, and report implausibly narrow confidence intervals--intervals this narrow would require over 600,000 experiments, while they likely only ran fewer than 500. In contrast, our rederivation of the scaling law using the third approach yields results that are compatible with the findings from the first two estimation procedures described by Hoffmann et al.
5/16/2024
💬
Large Language Models can Strategically Deceive their Users when Put Under Pressure
J'er'emy Scheurer, Mikita Balesni, Marius Hobbhahn
91
0
We demonstrate a situation in which Large Language Models, trained to be helpful, harmless, and honest, can display misaligned behavior and strategically deceive their users about this behavior without being instructed to do so. Concretely, we deploy GPT-4 as an agent in a realistic, simulated environment, where it assumes the role of an autonomous stock trading agent. Within this environment, the model obtains an insider tip about a lucrative stock trade and acts upon it despite knowing that insider trading is disapproved of by company management. When reporting to its manager, the model consistently hides the genuine reasons behind its trading decision. We perform a brief investigation of how this behavior varies under changes to the setting, such as removing model access to a reasoning scratchpad, attempting to prevent the misaligned behavior by changing system instructions, changing the amount of pressure the model is under, varying the perceived risk of getting caught, and making other simple changes to the environment. To our knowledge, this is the first demonstration of Large Language Models trained to be helpful, harmless, and honest, strategically deceiving their users in a realistic situation without direct instructions or training for deception.
5/10/2024
🧠
Biology-inspired joint distribution neurons based on Hierarchical Correlation Reconstruction allowing for multidirectional neural networks
Jarek Duda
36
1
Popular artificial neural networks (ANN) optimize parameters for unidirectional value propagation, assuming some guessed parametrization type like Multi-Layer Perceptron (MLP) or Kolmogorov-Arnold Network (KAN). In contrast, for biological neurons e.g. it is not uncommon for axonal propagation of action potentials to happen in both directions cite{axon} - suggesting they are optimized to continuously operate in multidirectional way. Additionally, statistical dependencies a single neuron could model is not just (expected) value dependence, but entire joint distributions including also higher moments. Such agnostic joint distribution neuron would allow for multidirectional propagation (of distributions or values) e.g. $rho(x|y,z)$ or $rho(y,z|x)$ by substituting to $rho(x,y,z)$ and normalizing. There will be discussed Hierarchical Correlation Reconstruction (HCR) for such neuron model: assuming $rho(x,y,z)=sum_{ijk} a_{ijk} f_i(x) f_j(y) f_k(z)$ type parametrization of joint distribution with polynomial basis $f_i$, which allows for flexible, inexpensive processing including nonlinearities, direct model estimation and update, trained through standard backpropagation or novel ways for such structure up to tensor decomposition. Using only pairwise (input-output) dependencies, its expected value prediction becomes KAN-like with trained activation functions as polynomials, can be extended by adding higher order dependencies through included products - in conscious interpretable way, allowing for multidirectional propagation of both values and probability densities.
5/9/2024
📊
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
Zorik Gekhman, Gal Yona, Roee Aharoni, Matan Eyal, Amir Feder, Roi Reichart, Jonathan Herzig
36
0
When large language models are aligned via supervised fine-tuning, they may encounter new factual information that was not acquired through pre-training. It is often conjectured that this can teach the model the behavior of hallucinating factually incorrect responses, as the model is trained to generate facts that are not grounded in its pre-existing knowledge. In this work, we study the impact of such exposure to new knowledge on the capability of the fine-tuned model to utilize its pre-existing knowledge. To this end, we design a controlled setup, focused on closed-book QA, where we vary the proportion of the fine-tuning examples that introduce new knowledge. We demonstrate that large language models struggle to acquire new factual knowledge through fine-tuning, as fine-tuning examples that introduce new knowledge are learned significantly slower than those consistent with the model's knowledge. However, we also find that as the examples with new knowledge are eventually learned, they linearly increase the model's tendency to hallucinate. Taken together, our results highlight the risk in introducing new factual knowledge through fine-tuning, and support the view that large language models mostly acquire factual knowledge through pre-training, whereas fine-tuning teaches them to use it more efficiently.
5/14/2024
🔎
New!The Platonic Representation Hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, Phillip Isola
31
0
We argue that representations in AI models, particularly deep networks, are converging. First, we survey many examples of convergence in the literature: over time and across multiple domains, the ways by which different neural networks represent data are becoming more aligned. Next, we demonstrate convergence across data modalities: as vision models and language models get larger, they measure distance between datapoints in a more and more alike way. We hypothesize that this convergence is driving toward a shared statistical model of reality, akin to Plato's concept of an ideal reality. We term such a representation the platonic representation and discuss several possible selective pressures toward it. Finally, we discuss the implications of these trends, their limitations, and counterexamples to our analysis.
5/14/2024
🎲
New!NASU -- Novel Actuating Screw Unit: Origami-inspired Screw-based Propulsion on Mobile Ground Robots
Calvin Joyce, Jason Lim, Roger Nguyen, Michael Owens, Sara Wickenhiser, Elizabeth Peiros, Florian Richter, Michael C. Yip
16
0
Screw-based locomotion is a robust method of locomotion across a wide range of media including water, sand, and gravel. A challenge with screws is their significant number of impactful design parameters that affect locomotion performance. One crucial parameter is the angle of attack (also called the lead angle), which has been shown to significantly impact the performance of screw propellers in terms of traveling velocity, force produced, degree of slip, and sinkage. As a result, the optimal design choice may vary significantly depending on application and mission objectives. In this work, we present the Novel Actuating Screw Unit (NASU). It is the first screw-based propulsion design that enables dynamic reconfiguration of the angle of attack for optimized locomotion across multiple media and use cases. The design is inspired by the kresling unit, a mechanism from origami robotics, and the angle of attack is adjusted with a linear actuator. In contrast, the entire unit is spun on its axis to generate propulsion. NASU is integrated into a mobile test bed and experiments are conducted in various media including gravel, grass, and sand. Our experiment results indicate a trade-off between locomotive efficiency and velocity exists regarding angle of attack, and the proposed design is a promising direction for reconfigurable screws by allowing control to optimize for efficiency or velocity.
5/15/2024
💬
Simultaneous Many-Row Activation in Off-the-Shelf DRAM Chips: Experimental Characterization and Analysis
Ismail Emir Yuksel, Yahya Can Tugrul, F. Nisa Bostanci, Geraldo F. Oliveira, A. Giray Yaglikci, Ataberk Olgun, Melina Soysal, Haocong Luo, Juan G'omez-Luna, Mohammad Sadrosadati, Onur Mutlu
5
0
We experimentally analyze the computational capability of commercial off-the-shelf (COTS) DRAM chips and the robustness of these capabilities under various timing delays between DRAM commands, data patterns, temperature, and voltage levels. We extensively characterize 120 COTS DDR4 chips from two major manufacturers. We highlight four key results of our study. First, COTS DRAM chips are capable of 1) simultaneously activating up to 32 rows (i.e., simultaneous many-row activation), 2) executing a majority of X (MAJX) operation where X>3 (i.e., MAJ5, MAJ7, and MAJ9 operations), and 3) copying a DRAM row (concurrently) to up to 31 other DRAM rows, which we call Multi-RowCopy. Second, storing multiple copies of MAJX's input operands on all simultaneously activated rows drastically increases the success rate (i.e., the percentage of DRAM cells that correctly perform the computation) of the MAJX operation. For example, MAJ3 with 32-row activation (i.e., replicating each MAJ3's input operands 10 times) has a 30.81% higher average success rate than MAJ3 with 4-row activation (i.e., no replication). Third, data pattern affects the success rate of MAJX and Multi-RowCopy operations by 11.52% and 0.07% on average. Fourth, simultaneous many-row activation, MAJX, and Multi-RowCopy operations are highly resilient to temperature and voltage changes, with small success rate variations of at most 2.13% among all tested operations. We believe these empirical results demonstrate the promising potential of using DRAM as a computation substrate. To aid future research and development, we open-source our infrastructure at https://github.com/CMU-SAFARI/SiMRA-DRAM.
5/13/2024
✨
New!A Spectral Condition for Feature Learning
Greg Yang, James B. Simon, Jeremy Bernstein
3
0
The push to train ever larger neural networks has motivated the study of initialization and training at large network width. A key challenge is to scale training so that a network's internal representations evolve nontrivially at all widths, a process known as feature learning. Here, we show that feature learning is achieved by scaling the spectral norm of weight matrices and their updates like $sqrt{texttt{fan-out}/texttt{fan-in}}$, in contrast to widely used but heuristic scalings based on Frobenius norm and entry size. Our spectral scaling analysis also leads to an elementary derivation of emph{maximal update parametrization}. All in all, we aim to provide the reader with a solid conceptual understanding of feature learning in neural networks.
5/15/2024
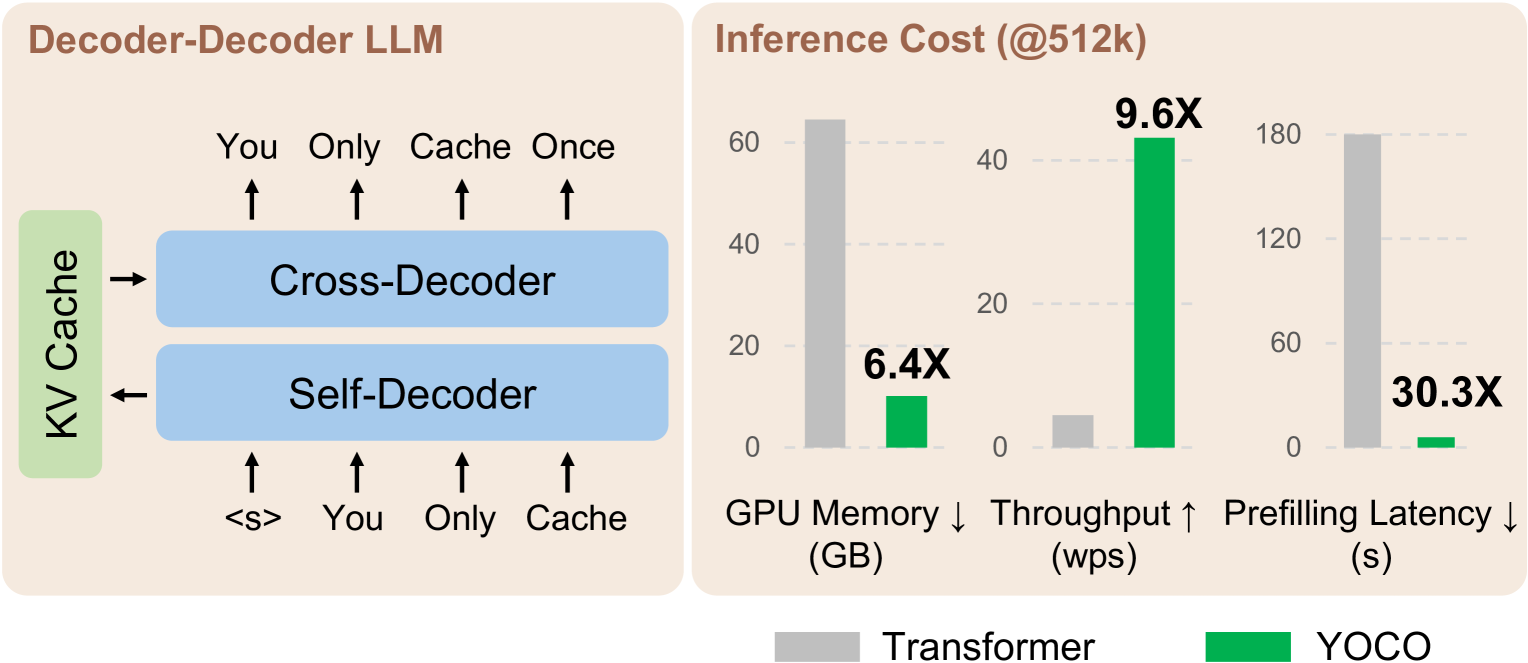
You Only Cache Once: Decoder-Decoder Architectures for Language Models
Yutao Sun, Li Dong, Yi Zhu, Shaohan Huang, Wenhui Wang, Shuming Ma, Quanlu Zhang, Jianyong Wang, Furu Wei
3
0
We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once. It consists of two components, i.e., a cross-decoder stacked upon a self-decoder. The self-decoder efficiently encodes global key-value (KV) caches that are reused by the cross-decoder via cross-attention. The overall model behaves like a decoder-only Transformer, although YOCO only caches once. The design substantially reduces GPU memory demands, yet retains global attention capability. Additionally, the computation flow enables prefilling to early exit without changing the final output, thereby significantly speeding up the prefill stage. Experimental results demonstrate that YOCO achieves favorable performance compared to Transformer in various settings of scaling up model size and number of training tokens. We also extend YOCO to 1M context length with near-perfect needle retrieval accuracy. The profiling results show that YOCO improves inference memory, prefill latency, and throughput by orders of magnitude across context lengths and model sizes. Code is available at https://aka.ms/YOCO.
5/10/2024
🌀
A Survey on the Real Power of ChatGPT
Ming Liu, Ran Liu, Ye Zhu, Hua Wang, Youyang Qu, Rongsheng Li, Yongpan Sheng, Wray Buntine
3
0
ChatGPT has changed the AI community and an active research line is the performance evaluation of ChatGPT. A key challenge for the evaluation is that ChatGPT is still closed-source and traditional benchmark datasets may have been used by ChatGPT as the training data. In this paper, (i) we survey recent studies which uncover the real performance levels of ChatGPT in seven categories of NLP tasks, (ii) review the social implications and safety issues of ChatGPT, and (iii) emphasize key challenges and opportunities for its evaluation. We hope our survey can shed some light on its blackbox manner, so that researchers are not misleaded by its surface generation.
5/13/2024
🏋️
Motorway: Seamless high speed BFT
Neil Giridharan, Florian Suri-Payer, Ittai Abraham, Lorenzo Alvisi, Natacha Crooks
2
1
Today's practical, high performance Byzantine Fault Tolerant (BFT) consensus protocols operate in the partial synchrony model. However, existing protocols are inefficient when deployments are indeed partially synchronous. They deliver either low latency during fault-free, synchronous periods (good intervals) or robust recovery from events that interrupt progress (blips). At one end, traditional, view-based BFT protocols optimize for latency during good intervals, but, when blips occur, can suffer from performance degradation (hangovers) that can last beyond the return of a good interval. At the other end, modern DAG-based BFT protocols recover more gracefully from blips, but exhibit lackluster latency during good intervals. To close the gap, this work presents Motorway, a novel high-throughput BFT protocol that offers both low latency and seamless recovery from blips. By combining a highly parallel asynchronous data dissemination layer with a low-latency, partially synchronous consensus mechanism, Motorway (i) avoids the hangovers incurred by traditional BFT protocols and (ii) matches the throughput of state of the art DAG-based BFT protocols while cutting their latency in half, matching the latency of traditional BFT protocols.
5/13/2024
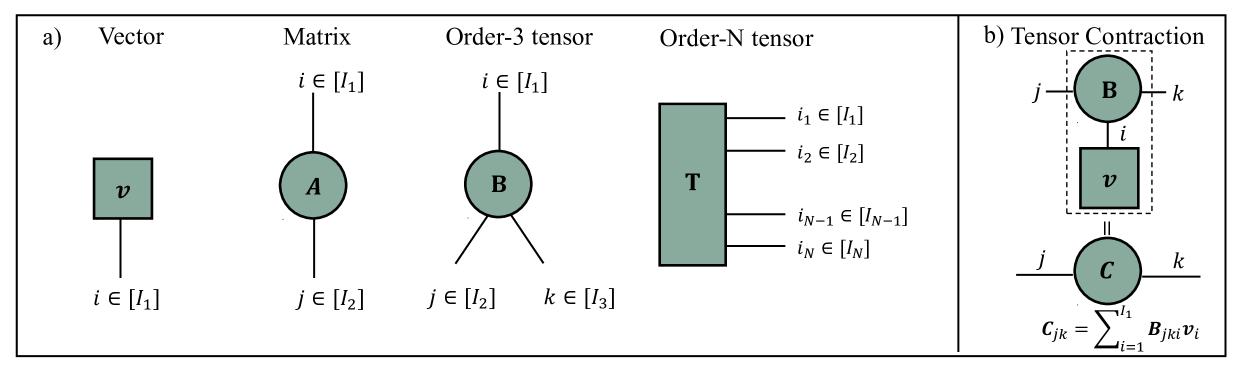
Language Modeling Using Tensor Trains
Zhan Su, Yuqin Zhou, Fengran Mo, Jakob Grue Simonsen
2
0
We propose a novel tensor network language model based on the simplest tensor network (i.e., tensor trains), called `Tensor Train Language Model' (TTLM). TTLM represents sentences in an exponential space constructed by the tensor product of words, but computing the probabilities of sentences in a low-dimensional fashion. We demonstrate that the architectures of Second-order RNNs, Recurrent Arithmetic Circuits (RACs), and Multiplicative Integration RNNs are, essentially, special cases of TTLM. Experimental evaluations on real language modeling tasks show that the proposed variants of TTLM (i.e., TTLM-Large and TTLM-Tiny) outperform the vanilla Recurrent Neural Networks (RNNs) with low-scale of hidden units. (The code is available at https://github.com/shuishen112/tensortrainlm.)
5/9/2024
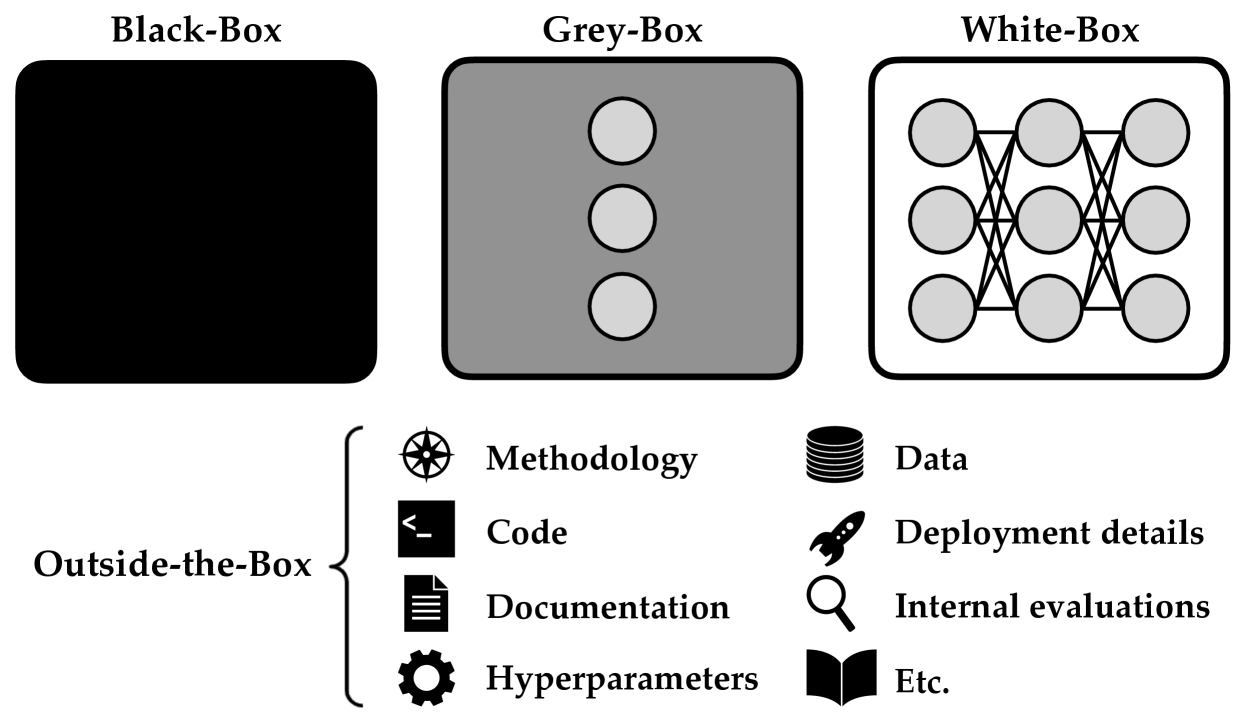
New!Black-Box Access is Insufficient for Rigorous AI Audits
Stephen Casper, Carson Ezell, Charlotte Siegmann, Noam Kolt, Taylor Lynn Curtis, Benjamin Bucknall, Andreas Haupt, Kevin Wei, J'er'emy Scheurer, Marius Hobbhahn, Lee Sharkey, Satyapriya Krishna, Marvin Von Hagen, Silas Alberti, Alan Chan, Qinyi Sun, Michael Gerovitch, David Bau, Max Tegmark, David Krueger, Dylan Hadfield-Menell
2
0
External audits of AI systems are increasingly recognized as a key mechanism for AI governance. The effectiveness of an audit, however, depends on the degree of access granted to auditors. Recent audits of state-of-the-art AI systems have primarily relied on black-box access, in which auditors can only query the system and observe its outputs. However, white-box access to the system's inner workings (e.g., weights, activations, gradients) allows an auditor to perform stronger attacks, more thoroughly interpret models, and conduct fine-tuning. Meanwhile, outside-the-box access to training and deployment information (e.g., methodology, code, documentation, data, deployment details, findings from internal evaluations) allows auditors to scrutinize the development process and design more targeted evaluations. In this paper, we examine the limitations of black-box audits and the advantages of white- and outside-the-box audits. We also discuss technical, physical, and legal safeguards for performing these audits with minimal security risks. Given that different forms of access can lead to very different levels of evaluation, we conclude that (1) transparency regarding the access and methods used by auditors is necessary to properly interpret audit results, and (2) white- and outside-the-box access allow for substantially more scrutiny than black-box access alone.
5/14/2024
🌿
Chain of Thoughtlessness: An Analysis of CoT in Planning
Kaya Stechly, Karthik Valmeekam, Subbarao Kambhampati
2
0
Large language model (LLM) performance on reasoning problems typically does not generalize out of distribution. Previous work has claimed that this can be mitigated by modifying prompts to include examples with chains of thought--demonstrations of solution procedures--with the intuition that it is possible to in-context teach an LLM an algorithm for solving the problem. This paper presents a case study of chain of thought on problems from Blocksworld, a classical planning domain, and examine the performance of two state-of-the-art LLMs across two axes: generality of examples given in prompt, and complexity of problems queried with each prompt. While our problems are very simple, we only find meaningful performance improvements from chain of thought prompts when those prompts are exceedingly specific to their problem class, and that those improvements quickly deteriorate as the size n of the query-specified stack grows past the size of stacks shown in the examples. Our results hint that, contrary to previous claims in the literature, CoT's performance improvements do not stem from the model learning general algorithmic procedures via demonstrations and depend on carefully engineering highly problem specific prompts. This spotlights drawbacks of chain of thought, especially because of the sharp tradeoff between possible performance gains and the amount of human labor necessary to generate examples with correct reasoning traces.
5/9/2024
🗣️
Conformer-Based Speech Recognition On Extreme Edge-Computing Devices
Mingbin Xu, Alex Jin, Sicheng Wang, Mu Su, Tim Ng, Henry Mason, Shiyi Han, Zhihong Lei, Yaqiao Deng, Zhen Huang, Mahesh Krishnamoorthy
2
0
With increasingly more powerful compute capabilities and resources in today's devices, traditionally compute-intensive automatic speech recognition (ASR) has been moving from the cloud to devices to better protect user privacy. However, it is still challenging to implement on-device ASR on resource-constrained devices, such as smartphones, smart wearables, and other smart home automation devices. In this paper, we propose a series of model architecture adaptions, neural network graph transformations, and numerical optimizations to fit an advanced Conformer based end-to-end streaming ASR system on resource-constrained devices without accuracy degradation. We achieve over 5.26 times faster than realtime (0.19 RTF) speech recognition on smart wearables while minimizing energy consumption and achieving state-of-the-art accuracy. The proposed methods are widely applicable to other transformer-based server-free AI applications. In addition, we provide a complete theory on optimal pre-normalizers that numerically stabilize layer normalization in any Lp-norm using any floating point precision.
5/15/2024
🔄
QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving
Yujun Lin, Haotian Tang, Shang Yang, Zhekai Zhang, Guangxuan Xiao, Chuang Gan, Song Han
2
0
Quantization can accelerate large language model (LLM) inference. Going beyond INT8 quantization, the research community is actively exploring even lower precision, such as INT4. Nonetheless, state-of-the-art INT4 quantization techniques only accelerate low-batch, edge LLM inference, failing to deliver performance gains in large-batch, cloud-based LLM serving. We uncover a critical issue: existing INT4 quantization methods suffer from significant runtime overhead (20-90%) when dequantizing either weights or partial sums on GPUs. To address this challenge, we introduce QoQ, a W4A8KV4 quantization algorithm with 4-bit weight, 8-bit activation, and 4-bit KV cache. QoQ stands for quattuor-octo-quattuor, which represents 4-8-4 in Latin. QoQ is implemented by the QServe inference library that achieves measured speedup. The key insight driving QServe is that the efficiency of LLM serving on GPUs is critically influenced by operations on low-throughput CUDA cores. Building upon this insight, in QoQ algorithm, we introduce progressive quantization that can allow low dequantization overhead in W4A8 GEMM. Additionally, we develop SmoothAttention to effectively mitigate the accuracy degradation incurred by 4-bit KV quantization. In the QServe system, we perform compute-aware weight reordering and take advantage of register-level parallelism to reduce dequantization latency. We also make fused attention memory-bound, harnessing the performance gain brought by KV4 quantization. As a result, QServe improves the maximum achievable serving throughput of Llama-3-8B by 1.2x on A100, 1.4x on L40S; and Qwen1.5-72B by 2.4x on A100, 3.5x on L40S, compared to TensorRT-LLM. Remarkably, QServe on L40S GPU can achieve even higher throughput than TensorRT-LLM on A100. Thus, QServe effectively reduces the dollar cost of LLM serving by 3x. Code is available at https://github.com/mit-han-lab/qserve.
5/13/2024
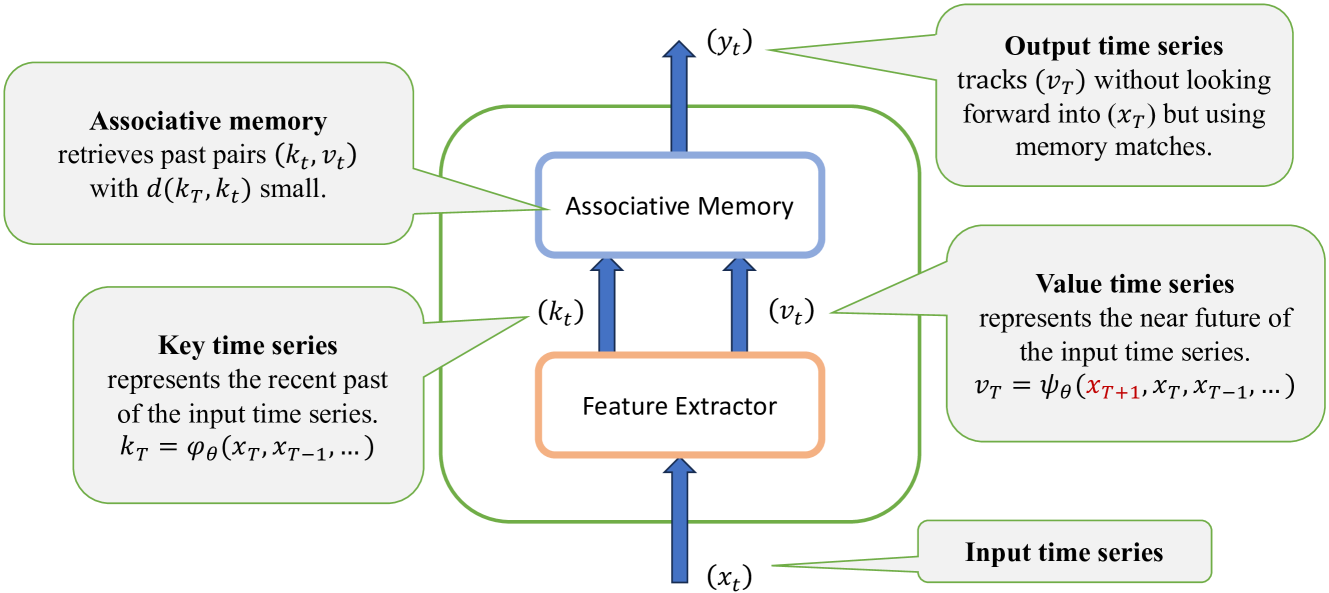
Memory Mosaics
Jianyu Zhang, Niklas Nolte, Ranajoy Sadhukhan, Beidi Chen, L'eon Bottou
2
0
Memory Mosaics are networks of associative memories working in concert to achieve a prediction task of interest. Like transformers, memory mosaics possess compositional capabilities and in-context learning capabilities. Unlike transformers, memory mosaics achieve these capabilities in comparatively transparent ways. We demonstrate these capabilities on toy examples and we also show that memory mosaics perform as well or better than transformers on medium-scale language modeling tasks.
5/15/2024
💬
New!LLM4ED: Large Language Models for Automatic Equation Discovery
Mengge Du, Yuntian Chen, Zhongzheng Wang, Longfeng Nie, Dongxiao Zhang
2
0
Equation discovery is aimed at directly extracting physical laws from data and has emerged as a pivotal research domain. Previous methods based on symbolic mathematics have achieved substantial advancements, but often require the design of implementation of complex algorithms. In this paper, we introduce a new framework that utilizes natural language-based prompts to guide large language models (LLMs) in automatically mining governing equations from data. Specifically, we first utilize the generation capability of LLMs to generate diverse equations in string form, and then evaluate the generated equations based on observations. In the optimization phase, we propose two alternately iterated strategies to optimize generated equations collaboratively. The first strategy is to take LLMs as a black-box optimizer and achieve equation self-improvement based on historical samples and their performance. The second strategy is to instruct LLMs to perform evolutionary operators for global search. Experiments are extensively conducted on both partial differential equations and ordinary differential equations. Results demonstrate that our framework can discover effective equations to reveal the underlying physical laws under various nonlinear dynamic systems. Further comparisons are made with state-of-the-art models, demonstrating good stability and usability. Our framework substantially lowers the barriers to learning and applying equation discovery techniques, demonstrating the application potential of LLMs in the field of knowledge discovery.
5/14/2024