AI Papers
Browse and discover the latest research papers on artificial intelligence, machine learning, and related fields.
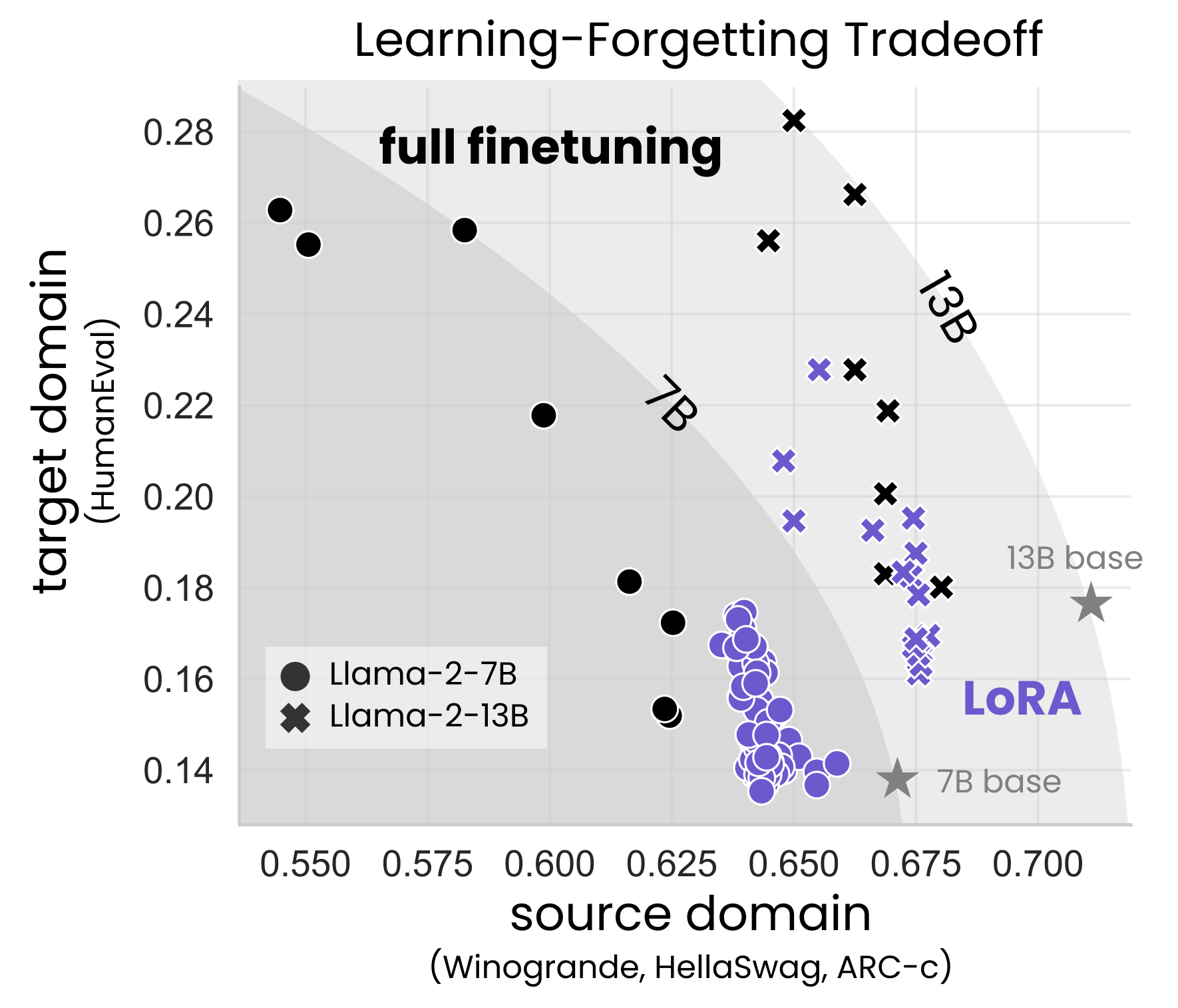
LoRA Learns Less and Forgets Less
Dan Biderman, Jose Gonzalez Ortiz, Jacob Portes, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, John P. Cunningham
177
0
Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In this work, we compare the performance of LoRA and full finetuning on two target domains, programming and mathematics. We consider both the instruction finetuning ($approx$100K prompt-response pairs) and continued pretraining ($approx$10B unstructured tokens) data regimes. Our results show that, in most settings, LoRA substantially underperforms full finetuning. Nevertheless, LoRA exhibits a desirable form of regularization: it better maintains the base model's performance on tasks outside the target domain. We show that LoRA provides stronger regularization compared to common techniques such as weight decay and dropout; it also helps maintain more diverse generations. We show that full finetuning learns perturbations with a rank that is 10-100X greater than typical LoRA configurations, possibly explaining some of the reported gaps. We conclude by proposing best practices for finetuning with LoRA.
5/17/2024
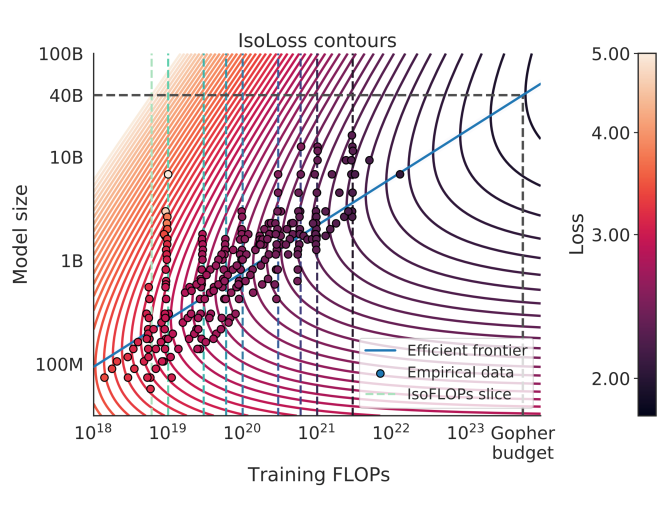
Chinchilla Scaling: A replication attempt
Tamay Besiroglu, Ege Erdil, Matthew Barnett, Josh You
124
0
Hoffmann et al. (2022) propose three methods for estimating a compute-optimal scaling law. We attempt to replicate their third estimation procedure, which involves fitting a parametric loss function to a reconstruction of data from their plots. We find that the reported estimates are inconsistent with their first two estimation methods, fail at fitting the extracted data, and report implausibly narrow confidence intervals--intervals this narrow would require over 600,000 experiments, while they likely only ran fewer than 500. In contrast, our rederivation of the scaling law using the third approach yields results that are compatible with the findings from the first two estimation procedures described by Hoffmann et al.
5/16/2024
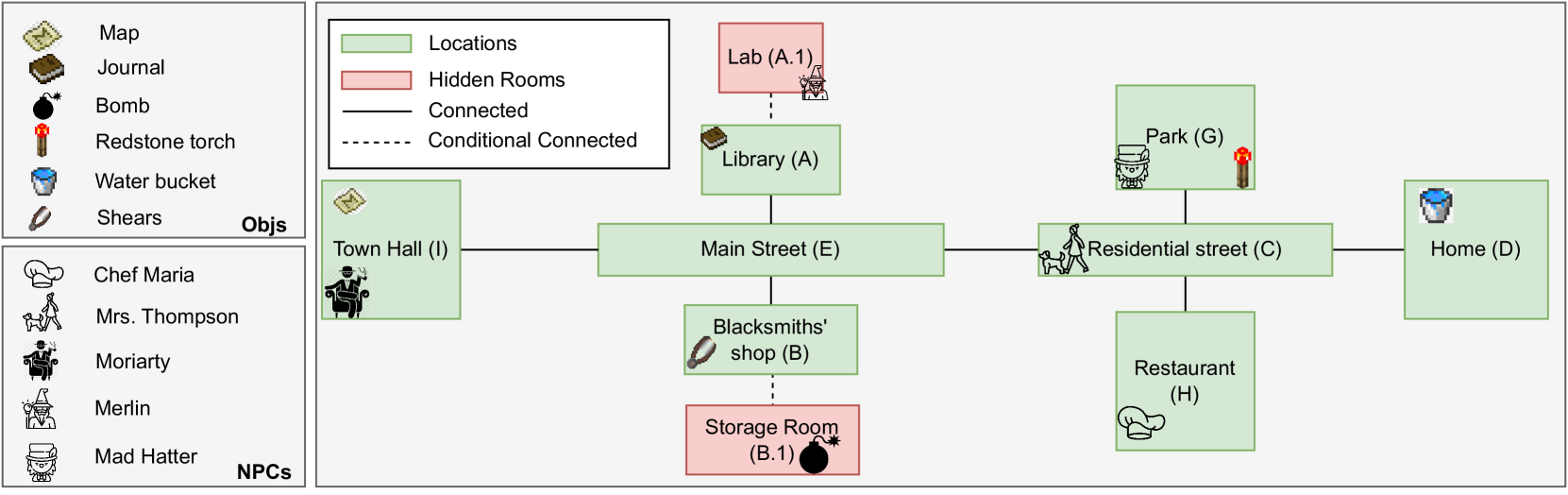
Player-Driven Emergence in LLM-Driven Game Narrative
Xiangyu Peng, Jessica Quaye, Weijia Xu, Portia Botchway, Chris Brockett, Bill Dolan, Nebojsa Jojic, Gabriel DesGarennes, Ken Lobb, Michael Xu, Jorge Leandro, Claire Jin, Sudha Rao
118
0
We explore how interaction with large language models (LLMs) can give rise to emergent behaviors, empowering players to participate in the evolution of game narratives. Our testbed is a text-adventure game in which players attempt to solve a mystery under a fixed narrative premise, but can freely interact with non-player characters generated by GPT-4, a large language model. We recruit 28 gamers to play the game and use GPT-4 to automatically convert the game logs into a node-graph representing the narrative in the player's gameplay. We find that through their interactions with the non-deterministic behavior of the LLM, players are able to discover interesting new emergent nodes that were not a part of the original narrative but have potential for being fun and engaging. Players that created the most emergent nodes tended to be those that often enjoy games that facilitate discovery, exploration and experimentation.
5/20/2024
New!Layer-Condensed KV Cache for Efficient Inference of Large Language Models
Haoyi Wu, Kewei Tu
115
0
Huge memory consumption has been a major bottleneck for deploying high-throughput large language models in real-world applications. In addition to the large number of parameters, the key-value (KV) cache for the attention mechanism in the transformer architecture consumes a significant amount of memory, especially when the number of layers is large for deep language models. In this paper, we propose a novel method that only computes and caches the KVs of a small number of layers, thus significantly saving memory consumption and improving inference throughput. Our experiments on large language models show that our method achieves up to 26$times$ higher throughput than standard transformers and competitive performance in language modeling and downstream tasks. In addition, our method is orthogonal to existing transformer memory-saving techniques, so it is straightforward to integrate them with our model, achieving further improvement in inference efficiency. Our code is available at https://github.com/whyNLP/LCKV.
5/20/2024

Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team
108
0
We present Chameleon, a family of early-fusion token-based mixed-modal models capable of understanding and generating images and text in any arbitrary sequence. We outline a stable training approach from inception, an alignment recipe, and an architectural parameterization tailored for the early-fusion, token-based, mixed-modal setting. The models are evaluated on a comprehensive range of tasks, including visual question answering, image captioning, text generation, image generation, and long-form mixed modal generation. Chameleon demonstrates broad and general capabilities, including state-of-the-art performance in image captioning tasks, outperforms Llama-2 in text-only tasks while being competitive with models such as Mixtral 8x7B and Gemini-Pro, and performs non-trivial image generation, all in a single model. It also matches or exceeds the performance of much larger models, including Gemini Pro and GPT-4V, according to human judgments on a new long-form mixed-modal generation evaluation, where either the prompt or outputs contain mixed sequences of both images and text. Chameleon marks a significant step forward in a unified modeling of full multimodal documents.
5/17/2024
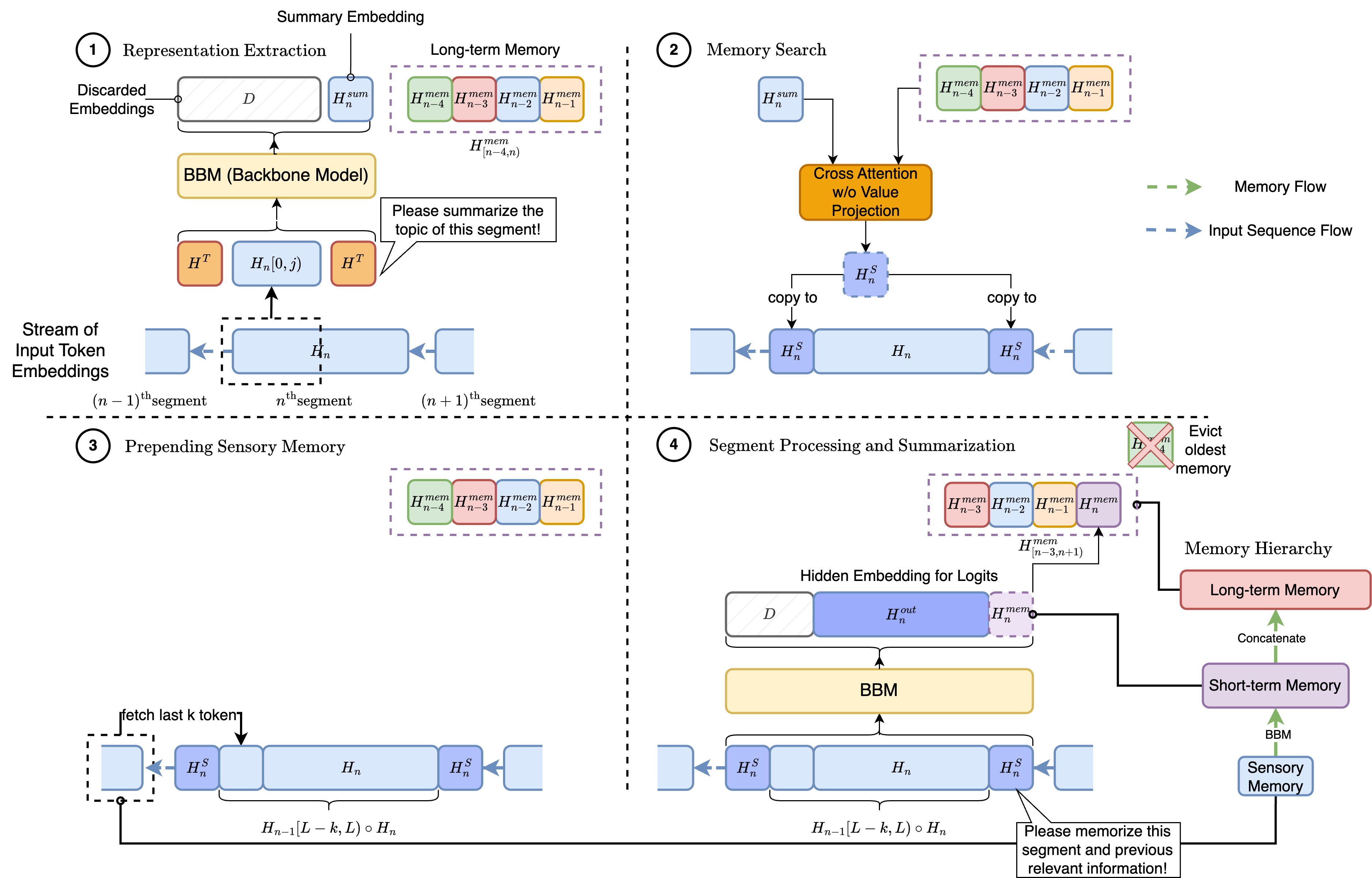
HMT: Hierarchical Memory Transformer for Long Context Language Processing
Zifan He, Zongyue Qin, Neha Prakriya, Yizhou Sun, Jason Cong
87
0
Transformer-based large language models (LLM) have been widely used in language processing applications. However, most of them restrict the context window that permits the model to attend to every token in the inputs. Previous works in recurrent models can memorize past tokens to enable unlimited context and maintain effectiveness. However, they have flat memory architectures, which have limitations in selecting and filtering information. Since humans are good at learning and self-adjustment, we speculate that imitating brain memory hierarchy is beneficial for model memorization. We propose the Hierarchical Memory Transformer (HMT), a novel framework that enables and improves models' long-context processing ability by imitating human memorization behavior. Leveraging memory-augmented segment-level recurrence, we organize the memory hierarchy by preserving tokens from early input token segments, passing memory embeddings along the sequence, and recalling relevant information from history. Evaluating general language modeling (Wikitext-103, PG-19) and question-answering tasks (PubMedQA), we show that HMT steadily improves the long-context processing ability of context-constrained and long-context models. With an additional 0.5% - 2% of parameters, HMT can easily plug in and augment future LLMs to handle long context effectively. Our code is open-sourced on Github: https://github.com/OswaldHe/HMT-pytorch.
5/15/2024

Sakuga-42M Dataset: Scaling Up Cartoon Research
Zhenglin Pan, Yu Zhu, Yuxuan Mu
84
0
Hand-drawn cartoon animation employs sketches and flat-color segments to create the illusion of motion. While recent advancements like CLIP, SVD, and Sora show impressive results in understanding and generating natural video by scaling large models with extensive datasets, they are not as effective for cartoons. Through our empirical experiments, we argue that this ineffectiveness stems from a notable bias in hand-drawn cartoons that diverges from the distribution of natural videos. Can we harness the success of the scaling paradigm to benefit cartoon research? Unfortunately, until now, there has not been a sizable cartoon dataset available for exploration. In this research, we propose the Sakuga-42M Dataset, the first large-scale cartoon animation dataset. Sakuga-42M comprises 42 million keyframes covering various artistic styles, regions, and years, with comprehensive semantic annotations including video-text description pairs, anime tags, content taxonomies, etc. We pioneer the benefits of such a large-scale cartoon dataset on comprehension and generation tasks by finetuning contemporary foundation models like Video CLIP, Video Mamba, and SVD, achieving outstanding performance on cartoon-related tasks. Our motivation is to introduce large-scaling to cartoon research and foster generalization and robustness in future cartoon applications. Dataset, Code, and Pretrained Models will be publicly available.
5/14/2024
🚀
GDPR: Is it worth it? Perceptions of workers who have experienced its implementation
Gerard Buckley, Tristan Caulfield, Ingolf Becker
72
0
The General Data Protection Regulation (GDPR) remains the gold standard in privacy and security regulation. We investigate how the cost and effort required to implement GDPR is viewed by workers who have also experienced the regulations' benefits as citizens: is it worth it? In a multi-stage study, we survey N = 273 & 102 individuals who remained working in the same companies before, during, and after the implementation of GDPR. The survey finds that participants recognise their rights when prompted but know little about their regulator. They have observed concrete changes to data practices in their workplaces and appreciate the trade-offs. They take comfort that their personal data is handled as carefully as their employers' client data. The very people who comply with and execute the GDPR consider it to be positive for their company, positive for privacy and not a pointless, bureaucratic regulation. This is rare as it contradicts the conventional negative narrative about regulation. Policymakers may wish to build upon this public support while it lasts and consider early feedback from a similar dual professional-consumer group as the GDPR evolves.
5/17/2024
💬
New!Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, Alex Smola
40
43
Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have primarily focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. Experimental results on ScienceQA and A-OKVQA benchmark datasets show the effectiveness of our proposed approach. With Multimodal-CoT, our model under 1 billion parameters achieves state-of-the-art performance on the ScienceQA benchmark. Our analysis indicates that Multimodal-CoT offers the advantages of mitigating hallucination and enhancing convergence speed. Code is publicly available at https://github.com/amazon-science/mm-cot.
5/21/2024
📊
MOMENT: A Family of Open Time-series Foundation Models
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, Artur Dubrawski
55
0
We introduce MOMENT, a family of open-source foundation models for general-purpose time series analysis. Pre-training large models on time series data is challenging due to (1) the absence of a large and cohesive public time series repository, and (2) diverse time series characteristics which make multi-dataset training onerous. Additionally, (3) experimental benchmarks to evaluate these models, especially in scenarios with limited resources, time, and supervision, are still in their nascent stages. To address these challenges, we compile a large and diverse collection of public time series, called the Time series Pile, and systematically tackle time series-specific challenges to unlock large-scale multi-dataset pre-training. Finally, we build on recent work to design a benchmark to evaluate time series foundation models on diverse tasks and datasets in limited supervision settings. Experiments on this benchmark demonstrate the effectiveness of our pre-trained models with minimal data and task-specific fine-tuning. Finally, we present several interesting empirical observations about large pre-trained time series models. Pre-trained models (AutonLab/MOMENT-1-large) and Time Series Pile (AutonLab/Timeseries-PILE) are available on Huggingface.
5/15/2024
📊
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
Zorik Gekhman, Gal Yona, Roee Aharoni, Matan Eyal, Amir Feder, Roi Reichart, Jonathan Herzig
36
0
When large language models are aligned via supervised fine-tuning, they may encounter new factual information that was not acquired through pre-training. It is often conjectured that this can teach the model the behavior of hallucinating factually incorrect responses, as the model is trained to generate facts that are not grounded in its pre-existing knowledge. In this work, we study the impact of such exposure to new knowledge on the capability of the fine-tuned model to utilize its pre-existing knowledge. To this end, we design a controlled setup, focused on closed-book QA, where we vary the proportion of the fine-tuning examples that introduce new knowledge. We demonstrate that large language models struggle to acquire new factual knowledge through fine-tuning, as fine-tuning examples that introduce new knowledge are learned significantly slower than those consistent with the model's knowledge. However, we also find that as the examples with new knowledge are eventually learned, they linearly increase the model's tendency to hallucinate. Taken together, our results highlight the risk in introducing new factual knowledge through fine-tuning, and support the view that large language models mostly acquire factual knowledge through pre-training, whereas fine-tuning teaches them to use it more efficiently.
5/14/2024
🔎
The Platonic Representation Hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, Phillip Isola
33
0
We argue that representations in AI models, particularly deep networks, are converging. First, we survey many examples of convergence in the literature: over time and across multiple domains, the ways by which different neural networks represent data are becoming more aligned. Next, we demonstrate convergence across data modalities: as vision models and language models get larger, they measure distance between datapoints in a more and more alike way. We hypothesize that this convergence is driving toward a shared statistical model of reality, akin to Plato's concept of an ideal reality. We term such a representation the platonic representation and discuss several possible selective pressures toward it. Finally, we discuss the implications of these trends, their limitations, and counterexamples to our analysis.
5/14/2024
🤖
AI Consciousness is Inevitable: A Theoretical Computer Science Perspective
Lenore Blum, Manuel Blum
21
0
We look at consciousness through the lens of Theoretical Computer Science, a branch of mathematics that studies computation under resource limitations. From this perspective, we develop a formal machine model for consciousness. The model is inspired by Alan Turing's simple yet powerful model of computation and Bernard Baars' theater model of consciousness. Though extremely simple, the model aligns at a high level with many of the major scientific theories of human and animal consciousness, supporting our claim that machine consciousness is inevitable.
5/20/2024
🎲
NASU -- Novel Actuating Screw Unit: Origami-inspired Screw-based Propulsion on Mobile Ground Robots
Calvin Joyce, Jason Lim, Roger Nguyen, Michael Owens, Sara Wickenhiser, Elizabeth Peiros, Florian Richter, Michael C. Yip
16
0
Screw-based locomotion is a robust method of locomotion across a wide range of media including water, sand, and gravel. A challenge with screws is their significant number of impactful design parameters that affect locomotion performance. One crucial parameter is the angle of attack (also called the lead angle), which has been shown to significantly impact the performance of screw propellers in terms of traveling velocity, force produced, degree of slip, and sinkage. As a result, the optimal design choice may vary significantly depending on application and mission objectives. In this work, we present the Novel Actuating Screw Unit (NASU). It is the first screw-based propulsion design that enables dynamic reconfiguration of the angle of attack for optimized locomotion across multiple media and use cases. The design is inspired by the kresling unit, a mechanism from origami robotics, and the angle of attack is adjusted with a linear actuator. In contrast, the entire unit is spun on its axis to generate propulsion. NASU is integrated into a mobile test bed and experiments are conducted in various media including gravel, grass, and sand. Our experiment results indicate a trade-off between locomotive efficiency and velocity exists regarding angle of attack, and the proposed design is a promising direction for reconfigurable screws by allowing control to optimize for efficiency or velocity.
5/15/2024

How Far Are We From AGI
Tao Feng, Chuanyang Jin, Jingyu Liu, Kunlun Zhu, Haoqin Tu, Zirui Cheng, Guanyu Lin, Jiaxuan You
13
0
The evolution of artificial intelligence (AI) has profoundly impacted human society, driving significant advancements in multiple sectors. Yet, the escalating demands on AI have highlighted the limitations of AI's current offerings, catalyzing a movement towards Artificial General Intelligence (AGI). AGI, distinguished by its ability to execute diverse real-world tasks with efficiency and effectiveness comparable to human intelligence, reflects a paramount milestone in AI evolution. While existing works have summarized specific recent advancements of AI, they lack a comprehensive discussion of AGI's definitions, goals, and developmental trajectories. Different from existing survey papers, this paper delves into the pivotal questions of our proximity to AGI and the strategies necessary for its realization through extensive surveys, discussions, and original perspectives. We start by articulating the requisite capability frameworks for AGI, integrating the internal, interface, and system dimensions. As the realization of AGI requires more advanced capabilities and adherence to stringent constraints, we further discuss necessary AGI alignment technologies to harmonize these factors. Notably, we emphasize the importance of approaching AGI responsibly by first defining the key levels of AGI progression, followed by the evaluation framework that situates the status-quo, and finally giving our roadmap of how to reach the pinnacle of AGI. Moreover, to give tangible insights into the ubiquitous impact of the integration of AI, we outline existing challenges and potential pathways toward AGI in multiple domains. In sum, serving as a pioneering exploration into the current state and future trajectory of AGI, this paper aims to foster a collective comprehension and catalyze broader public discussions among researchers and practitioners on AGI.
5/17/2024
🏋️
Special Characters Attack: Toward Scalable Training Data Extraction From Large Language Models
Yang Bai, Ge Pei, Jindong Gu, Yong Yang, Xingjun Ma
10
0
Large language models (LLMs) have achieved remarkable performance on a wide range of tasks. However, recent studies have shown that LLMs can memorize training data and simple repeated tokens can trick the model to leak the data. In this paper, we take a step further and show that certain special characters or their combinations with English letters are stronger memory triggers, leading to more severe data leakage. The intuition is that, since LLMs are trained with massive data that contains a substantial amount of special characters (e.g. structural symbols {, } of JSON files, and @, # in emails and online posts), the model may memorize the co-occurrence between these special characters and the raw texts. This motivates us to propose a simple but effective Special Characters Attack (SCA) to induce training data leakage. Our experiments verify the high effectiveness of SCA against state-of-the-art LLMs: they can leak diverse training data, such as code corpus, web pages, and personally identifiable information, and sometimes generate non-stop outputs as a byproduct. We further show that the composition of the training data corpus can be revealed by inspecting the leaked data -- one crucial piece of information for pre-training high-performance LLMs. Our work can help understand the sensitivity of LLMs to special characters and identify potential areas for improvement.
5/21/2024
🤿
New!An Analysis of Quantile Temporal-Difference Learning
Mark Rowland, R'emi Munos, Mohammad Gheshlaghi Azar, Yunhao Tang, Georg Ostrovski, Anna Harutyunyan, Karl Tuyls, Marc G. Bellemare, Will Dabney
0
16
We analyse quantile temporal-difference learning (QTD), a distributional reinforcement learning algorithm that has proven to be a key component in several successful large-scale applications of reinforcement learning. Despite these empirical successes, a theoretical understanding of QTD has proven elusive until now. Unlike classical TD learning, which can be analysed with standard stochastic approximation tools, QTD updates do not approximate contraction mappings, are highly non-linear, and may have multiple fixed points. The core result of this paper is a proof of convergence to the fixed points of a related family of dynamic programming procedures with probability 1, putting QTD on firm theoretical footing. The proof establishes connections between QTD and non-linear differential inclusions through stochastic approximation theory and non-smooth analysis.
5/21/2024
💬
Thinking Tokens for Language Modeling
David Herel, Tomas Mikolov
6
0
How much is 56 times 37? Language models often make mistakes in these types of difficult calculations. This is usually explained by their inability to perform complex reasoning. Since language models rely on large training sets and great memorization capability, naturally they are not equipped to run complex calculations. However, one can argue that humans also cannot perform this calculation immediately and require a considerable amount of time to construct the solution. In order to enhance the generalization capability of language models, and as a parallel to human behavior, we propose to use special 'thinking tokens' which allow the model to perform much more calculations whenever a complex problem is encountered.
5/15/2024
💬
LLM4ED: Large Language Models for Automatic Equation Discovery
Mengge Du, Yuntian Chen, Zhongzheng Wang, Longfeng Nie, Dongxiao Zhang
5
0
Equation discovery is aimed at directly extracting physical laws from data and has emerged as a pivotal research domain. Previous methods based on symbolic mathematics have achieved substantial advancements, but often require the design of implementation of complex algorithms. In this paper, we introduce a new framework that utilizes natural language-based prompts to guide large language models (LLMs) in automatically mining governing equations from data. Specifically, we first utilize the generation capability of LLMs to generate diverse equations in string form, and then evaluate the generated equations based on observations. In the optimization phase, we propose two alternately iterated strategies to optimize generated equations collaboratively. The first strategy is to take LLMs as a black-box optimizer and achieve equation self-improvement based on historical samples and their performance. The second strategy is to instruct LLMs to perform evolutionary operators for global search. Experiments are extensively conducted on both partial differential equations and ordinary differential equations. Results demonstrate that our framework can discover effective equations to reveal the underlying physical laws under various nonlinear dynamic systems. Further comparisons are made with state-of-the-art models, demonstrating good stability and usability. Our framework substantially lowers the barriers to learning and applying equation discovery techniques, demonstrating the application potential of LLMs in the field of knowledge discovery.
5/14/2024
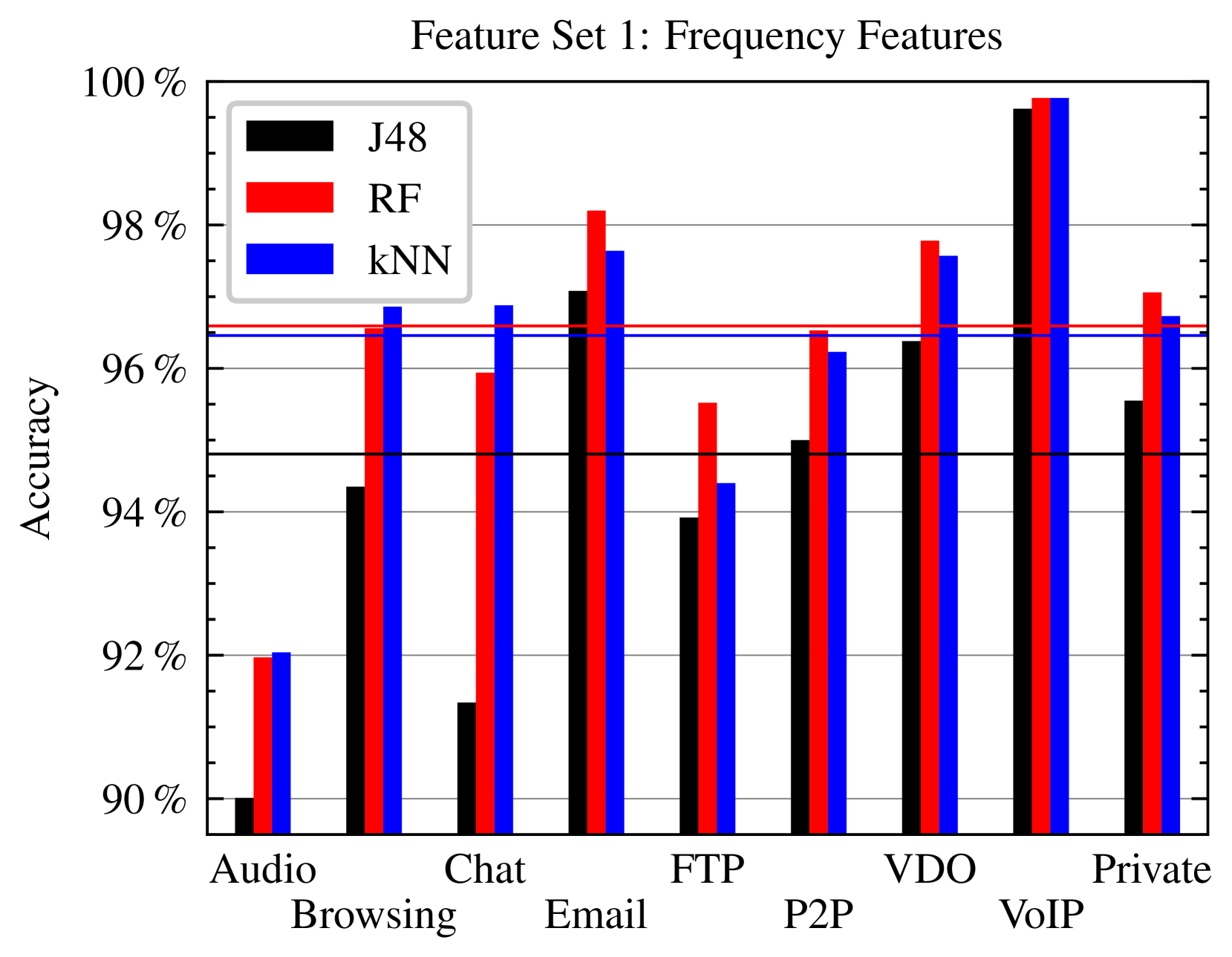
Distinguishing Tor From Other Encrypted Network Traffic Through Character Analysis
Pitpimon Choorod, Tobias J. Bauer, Andreas A{ss}muth
4
0
For journalists reporting from a totalitarian regime, whistleblowers and resistance fighters, the anonymous use of cloud services on the Internet can be vital for survival. The Tor network provides a free and widely used anonymization service for everyone. However, there are different approaches to distinguishing Tor from non-Tor encrypted network traffic, most recently only due to the (relative) frequencies of hex digits in a single encrypted payload packet. While conventional data traffic is usually encrypted once, but at least three times in the case of Tor due to the structure and principle of the Tor network, we have examined to what extent the number of encryptions contributes to being able to distinguish Tor from non-Tor encrypted data traffic.
5/16/2024