Revisiting Text-to-Image Evaluation with Gecko: On Metrics, Prompts, and Human Ratings
2404.16820
0
0
🧠
Abstract
While text-to-image (T2I) generative models have become ubiquitous, they do not necessarily generate images that align with a given prompt. While previous work has evaluated T2I alignment by proposing metrics, benchmarks, and templates for collecting human judgements, the quality of these components is not systematically measured. Human-rated prompt sets are generally small and the reliability of the ratings -- and thereby the prompt set used to compare models -- is not evaluated. We address this gap by performing an extensive study evaluating auto-eval metrics and human templates. We provide three main contributions: (1) We introduce a comprehensive skills-based benchmark that can discriminate models across different human templates. This skills-based benchmark categorises prompts into sub-skills, allowing a practitioner to pinpoint not only which skills are challenging, but at what level of complexity a skill becomes challenging. (2) We gather human ratings across four templates and four T2I models for a total of >100K annotations. This allows us to understand where differences arise due to inherent ambiguity in the prompt and where they arise due to differences in metric and model quality. (3) Finally, we introduce a new QA-based auto-eval metric that is better correlated with human ratings than existing metrics for our new dataset, across different human templates, and on TIFA160.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper addresses a gap in the evaluation of text-to-image (T2I) generative models, which are models that generate images from text prompts.
- While previous work has proposed metrics, benchmarks, and templates for collecting human judgements to evaluate T2I model alignment with prompts, the quality of these components is not systematically measured.
- The paper aims to provide a comprehensive evaluation of auto-eval metrics and human templates used to assess T2I models.
Plain English Explanation
Text-to-image (T2I) models are AI systems that can generate images based on textual descriptions or prompts. While these models have become widely used, they don't always produce images that perfectly match the given prompt. Previous research has tried to address this by developing ways to measure how well the generated images align with the prompts, such as proposing new evaluation metrics and templates for collecting human feedback.
However, the quality and reliability of these evaluation components have not been thoroughly examined. The human-rated prompt sets used to compare models are often small, and the reliability of the human ratings is not evaluated. This makes it difficult to know how robust the evaluations are and how well they reflect the actual performance of the T2I models.
This paper aims to fill this gap by conducting an extensive study to evaluate the auto-eval metrics and human templates used for assessing T2I model performance. The key contributions are:
-
Introducing a comprehensive skills-based benchmark that can identify which specific skills or capabilities a T2I model struggles with.
-
Gathering a large dataset of over 100,000 human ratings across different prompts and T2I models to understand the sources of differences in performance.
-
Developing a new QA-based auto-eval metric that correlates better with human ratings than existing metrics.
By rigorously evaluating the evaluation tools themselves, the paper provides a more robust and insightful way to assess the true capabilities and limitations of T2I models.
Technical Explanation
The paper addresses the challenge of comprehensively evaluating text-to-image (T2I) generative models, which are AI systems that can produce images from textual descriptions or prompts. While T2I models have become ubiquitous, the images they generate do not always align well with the given prompt.
Previous research has attempted to address this by proposing metrics, benchmarks, and templates for collecting human judgements to evaluate T2I model alignment. However, the quality and reliability of these evaluation components have not been systematically measured.
The key contributions of the paper are:
-
A comprehensive skills-based benchmark that can discriminate T2I model performance across different human prompts. This benchmark categorizes prompts into sub-skills, allowing practitioners to identify which specific capabilities a model struggles with and at what level of complexity.
-
A large dataset of over 100,000 human ratings across four different prompt templates and four T2I models. This allows the researchers to understand where differences in model performance arise due to inherent ambiguity in the prompts versus differences in metric and model quality.
-
A new QA-based auto-eval metric that correlates better with human ratings than existing metrics, both on the new dataset and on the TIFA160 benchmark.
The paper's systematic evaluation of the evaluation tools themselves provides a more robust and nuanced understanding of T2I model capabilities and limitations, going beyond the limitations of existing bias and evaluation frameworks.
Critical Analysis
The paper presents a thorough and well-designed study to address an important gap in the evaluation of text-to-image generative models. By carefully examining the quality and reliability of the evaluation components used in prior research, the authors provide valuable insights that can improve how we assess the performance of these AI systems.
One potential limitation is the relatively narrow focus on alignment between prompts and generated images. While this is a crucial aspect of T2I model performance, other factors like image quality, diversity, and creativity may also be important considerations. The paper acknowledges this and suggests that the proposed evaluation framework could be extended to cover these additional dimensions.
Additionally, the paper does not delve deeply into the implications of its findings for the broader field of text-to-image generation. Further research could explore how the insights from this study can inform the development of more robust and reliable T2I models, as well as the use of rich human feedback to improve model performance.
Overall, this paper makes a valuable contribution by critically examining the tools used to evaluate T2I models and providing a more comprehensive and reliable framework for assessing their alignment with textual prompts. The insights and methods presented here could serve as a foundation for optimizing prompts and improving the development of these generative AI systems.
Conclusion
This paper addresses a crucial gap in the evaluation of text-to-image (T2I) generative models by systematically examining the quality and reliability of the evaluation components used in prior research. The key contributions include a comprehensive skills-based benchmark, a large dataset of human ratings, and a new QA-based auto-eval metric that correlates better with human judgements.
By providing a more robust and nuanced understanding of T2I model capabilities and limitations, this work lays the groundwork for the development of more reliable and effective generative AI systems. The insights from this study can also inform the use of rich human feedback and prompt optimization to further enhance the performance of T2I models.
Overall, this paper represents an important step forward in the objective and rigorous evaluation of text-to-image generation, which is crucial for the continued advancement and responsible deployment of these powerful AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
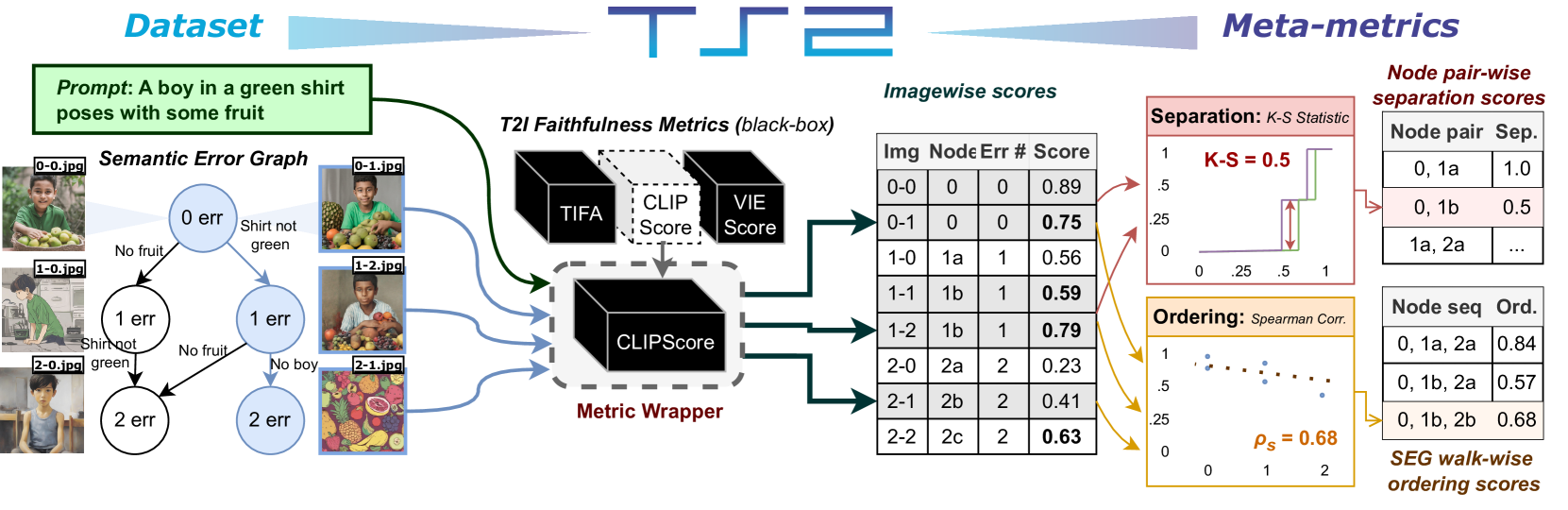
Who Evaluates the Evaluations? Objectively Scoring Text-to-Image Prompt Coherence Metrics with T2IScoreScore (TS2)
Michael Saxon, Fatima Jahara, Mahsa Khoshnoodi, Yujie Lu, Aditya Sharma, William Yang Wang
0
0
With advances in the quality of text-to-image (T2I) models has come interest in benchmarking their prompt faithfulness-the semantic coherence of generated images to the prompts they were conditioned on. A variety of T2I faithfulness metrics have been proposed, leveraging advances in cross-modal embeddings and vision-language models (VLMs). However, these metrics are not rigorously compared and benchmarked, instead presented against few weak baselines by correlation to human Likert scores over a set of easy-to-discriminate images. We introduce T2IScoreScore (TS2), a curated set of semantic error graphs containing a prompt and a set increasingly erroneous images. These allow us to rigorously judge whether a given prompt faithfulness metric can correctly order images with respect to their objective error count and significantly discriminate between different error nodes, using meta-metric scores derived from established statistical tests. Surprisingly, we find that the state-of-the-art VLM-based metrics (e.g., TIFA, DSG, LLMScore, VIEScore) we tested fail to significantly outperform simple feature-based metrics like CLIPScore, particularly on a hard subset of naturally-occurring T2I model errors. TS2 will enable the development of better T2I prompt faithfulness metrics through more rigorous comparison of their conformity to expected orderings and separations under objective criteria.
4/8/2024

Evaluating Text-to-Image Synthesis: Survey and Taxonomy of Image Quality Metrics
Sebastian Hartwig, Dominik Engel, Leon Sick, Hannah Kniesel, Tristan Payer, Poonam Poonam, Michael Glockler, Alex Bauerle, Timo Ropinski
0
0
Recent advances in text-to-image synthesis enabled through a combination of language and vision foundation models have led to a proliferation of the tools available and an increased attention to the field. When conducting text-to-image synthesis, a central goal is to ensure that the content between text and image is aligned. As such, there exist numerous evaluation metrics that aim to mimic human judgement. However, it is often unclear which metric to use for evaluating text-to-image synthesis systems as their evaluation is highly nuanced. In this work, we provide a comprehensive overview of existing text-to-image evaluation metrics. Based on our findings, we propose a new taxonomy for categorizing these metrics. Our taxonomy is grounded in the assumption that there are two main quality criteria, namely compositionality and generality, which ideally map to human preferences. Ultimately, we derive guidelines for practitioners conducting text-to-image evaluation, discuss open challenges of evaluation mechanisms, and surface limitations of current metrics.
4/16/2024
🤯
Survey of Bias In Text-to-Image Generation: Definition, Evaluation, and Mitigation
Yixin Wan, Arjun Subramonian, Anaelia Ovalle, Zongyu Lin, Ashima Suvarna, Christina Chance, Hritik Bansal, Rebecca Pattichis, Kai-Wei Chang
0
0
The recent advancement of large and powerful models with Text-to-Image (T2I) generation abilities -- such as OpenAI's DALLE-3 and Google's Gemini -- enables users to generate high-quality images from textual prompts. However, it has become increasingly evident that even simple prompts could cause T2I models to exhibit conspicuous social bias in generated images. Such bias might lead to both allocational and representational harms in society, further marginalizing minority groups. Noting this problem, a large body of recent works has been dedicated to investigating different dimensions of bias in T2I systems. However, an extensive review of these studies is lacking, hindering a systematic understanding of current progress and research gaps. We present the first extensive survey on bias in T2I generative models. In this survey, we review prior studies on dimensions of bias: Gender, Skintone, and Geo-Culture. Specifically, we discuss how these works define, evaluate, and mitigate different aspects of bias. We found that: (1) while gender and skintone biases are widely studied, geo-cultural bias remains under-explored; (2) most works on gender and skintone bias investigated occupational association, while other aspects are less frequently studied; (3) almost all gender bias works overlook non-binary identities in their studies; (4) evaluation datasets and metrics are scattered, with no unified framework for measuring biases; and (5) current mitigation methods fail to resolve biases comprehensively. Based on current limitations, we point out future research directions that contribute to human-centric definitions, evaluations, and mitigation of biases. We hope to highlight the importance of studying biases in T2I systems, as well as encourage future efforts to holistically understand and tackle biases, building fair and trustworthy T2I technologies for everyone.
5/3/2024
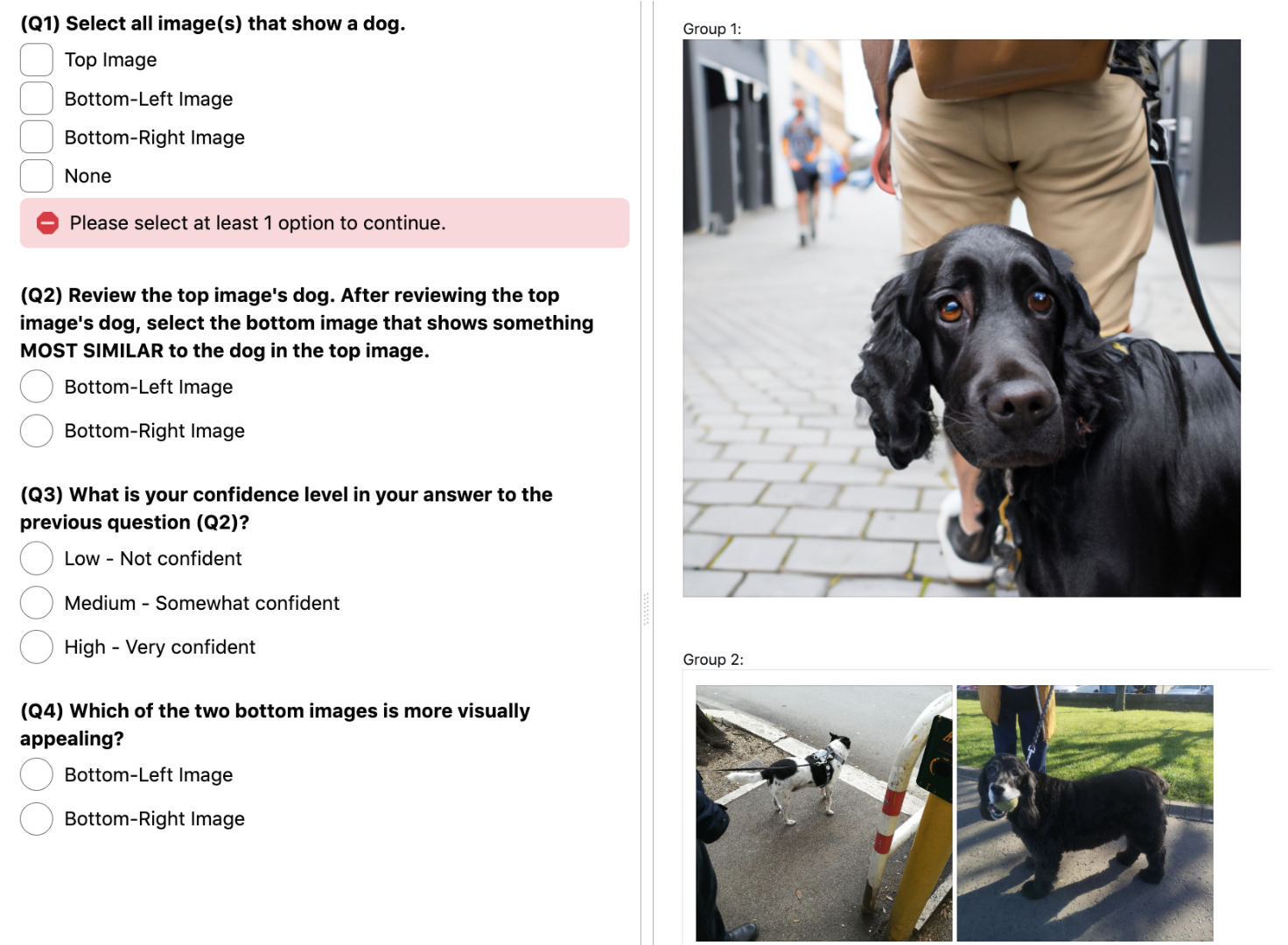
Towards Geographic Inclusion in the Evaluation of Text-to-Image Models
Melissa Hall, Samuel J. Bell, Candace Ross, Adina Williams, Michal Drozdzal, Adriana Romero Soriano
0
0
Rapid progress in text-to-image generative models coupled with their deployment for visual content creation has magnified the importance of thoroughly evaluating their performance and identifying potential biases. In pursuit of models that generate images that are realistic, diverse, visually appealing, and consistent with the given prompt, researchers and practitioners often turn to automated metrics to facilitate scalable and cost-effective performance profiling. However, commonly-used metrics often fail to account for the full diversity of human preference; often even in-depth human evaluations face challenges with subjectivity, especially as interpretations of evaluation criteria vary across regions and cultures. In this work, we conduct a large, cross-cultural study to study how much annotators in Africa, Europe, and Southeast Asia vary in their perception of geographic representation, visual appeal, and consistency in real and generated images from state-of-the art public APIs. We collect over 65,000 image annotations and 20 survey responses. We contrast human annotations with common automated metrics, finding that human preferences vary notably across geographic location and that current metrics do not fully account for this diversity. For example, annotators in different locations often disagree on whether exaggerated, stereotypical depictions of a region are considered geographically representative. In addition, the utility of automatic evaluations is dependent on assumptions about their set-up, such as the alignment of feature extractors with human perception of object similarity or the definition of appeal captured in reference datasets used to ground evaluations. We recommend steps for improved automatic and human evaluations.
5/8/2024