Recommender Systems in the Era of Large Language Models (LLMs)
2307.02046
3
0
Abstract
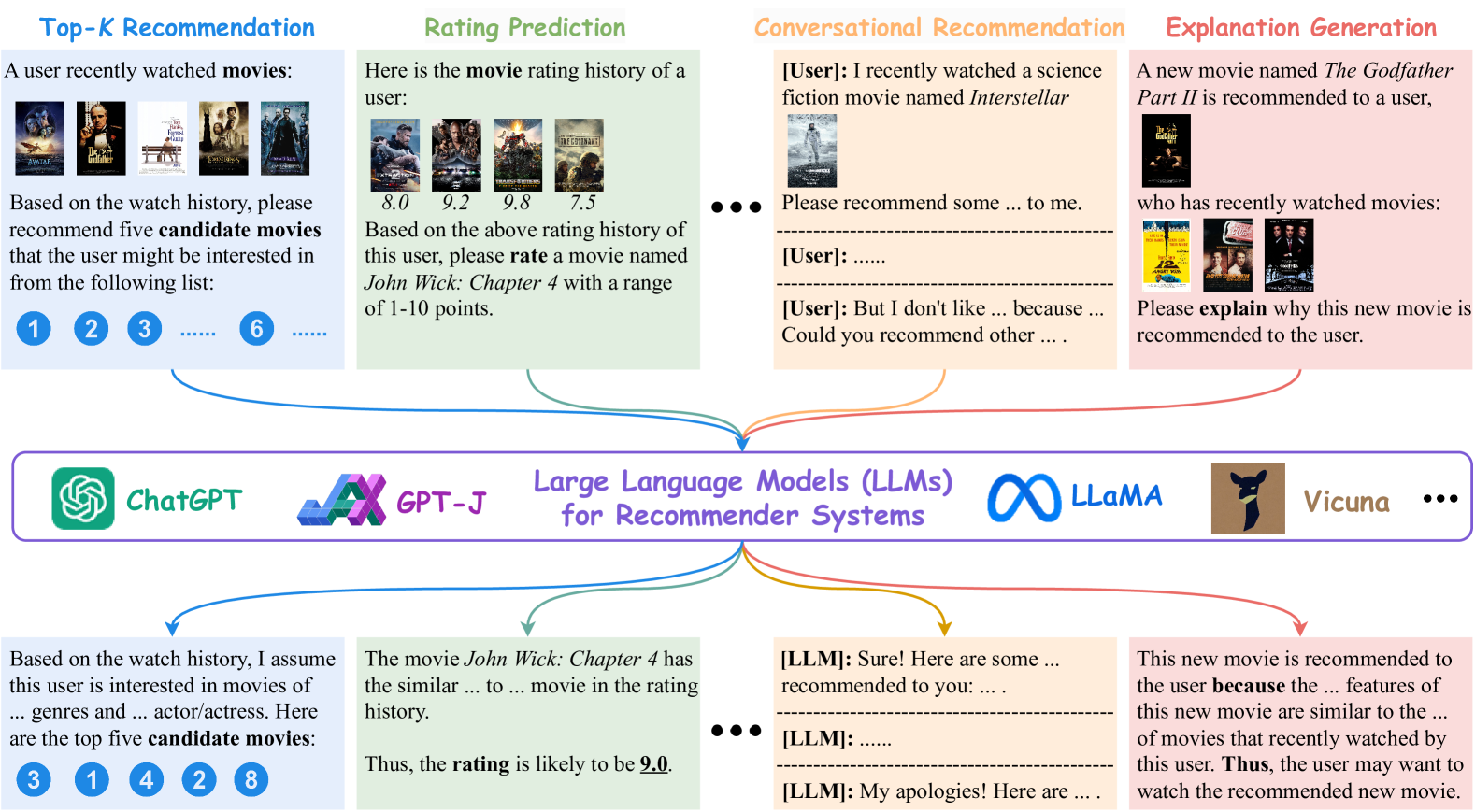
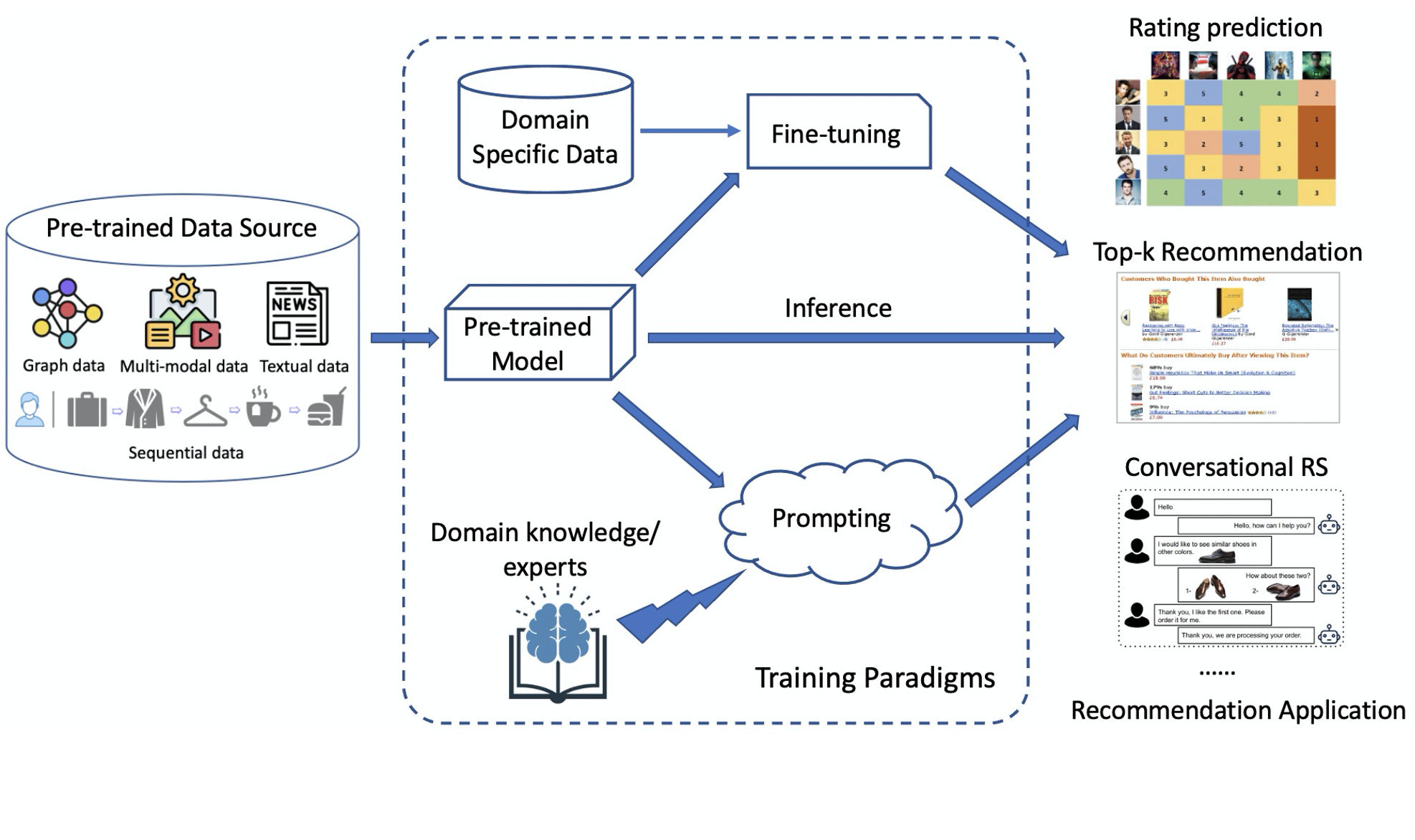
With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Examines the impact of large language models (LLMs) on recommender systems
- Discusses how LLMs can enable new approaches to personalized recommendation through techniques like in-context learning and prompting
- Explores how LLMs can be adapted and leveraged to advance recommender systems research and applications
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown remarkable capabilities in tasks like text generation and natural language understanding. This paper examines how these powerful AI models can be used to improve recommender systems - the systems that suggest products, content, or information to users based on their preferences and behavior.
One key benefit of LLMs is their ability to learn from limited data through techniques like in-context learning and prompting. This means that recommender systems can potentially provide personalized recommendations for users without requiring large amounts of historical data about their preferences. The paper discusses how LLMs can be fine-tuned or prompted to generate recommendations tailored to individual users.
Additionally, the paper explores how the underlying language modeling capabilities of LLMs can be adapted and leveraged to advance recommender systems research. Researchers can use LLMs as "research assistants" to help generate hypotheses, analyze data, and even write up findings - accelerating the pace of progress in this field.
Overall, the paper highlights the significant potential for LLMs to transform and enhance recommender systems, enabling more personalized and effective recommendations for users across a variety of domains.
Technical Explanation
The paper first provides an overview of the current state of recommender systems and the emerging role of large language models (LLMs) in this domain. It discusses how the pre-training and fine-tuning capabilities of LLMs, as well as their in-context learning and prompting abilities, can be leveraged to develop more personalized recommendation approaches.
The authors then delve into specific techniques for adapting LLMs for recommender systems. This includes methods for fine-tuning LLMs on recommendation-specific data, as well as ways to use prompting to guide LLMs to generate personalized recommendations. The paper also examines how the underlying language modeling capabilities of LLMs can be utilized to advance recommender systems research, such as using LLMs as "research assistants" to help generate hypotheses, analyze data, and even write up findings.
Through a series of experiments and case studies, the paper demonstrates the effectiveness of LLM-based approaches in delivering personalized recommendations. It highlights how these techniques can outperform traditional recommender systems, particularly in scenarios with limited user data.
Critical Analysis
The paper presents a compelling case for the integration of large language models (LLMs) into recommender systems. It astutely identifies the key strengths of LLMs, such as their ability to learn from limited data and generate personalized content, and explores how these capabilities can be leveraged to improve recommendation performance.
One potential limitation discussed in the paper is the challenge of adapting LLMs to specific recommendation domains and maintaining their performance as the model is fine-tuned. The authors acknowledge the need for further research to address this challenge and ensure the scalability and robustness of LLM-based recommender systems.
Additionally, the paper does not delve deeply into potential privacy and ethical concerns that may arise from the use of LLMs in recommender systems. As these models can generate highly personalized content, it will be crucial to consider the implications for user privacy and develop appropriate safeguards and oversight mechanisms.
Overall, the paper provides a well-reasoned and insightful exploration of the intersection between large language models and recommender systems. It encourages readers to think critically about the potential benefits and challenges of this emerging approach, and to consider the broader societal implications as these technologies continue to evolve.
Conclusion
This paper highlights the transformative potential of large language models (LLMs) in the field of recommender systems. By leveraging the powerful pre-training, fine-tuning, and in-context learning capabilities of LLMs, researchers can develop more personalized and effective recommendation approaches that can outperform traditional techniques, particularly in scenarios with limited user data.
The paper also demonstrates how the underlying language modeling capabilities of LLMs can be adapted and leveraged to advance recommender systems research, with LLMs serving as valuable "research assistants" to help generate hypotheses, analyze data, and even write up findings.
As the integration of LLMs and recommender systems continues to evolve, it will be crucial to address the challenges of domain adaptation and to consider the broader ethical and privacy implications of these powerful AI technologies. Nonetheless, the insights and techniques presented in this paper offer a promising path forward for the future of personalized recommendation and decision-making support systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
LLM-Rec: Personalized Recommendation via Prompting Large Language Models
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Christopher Leung, Jiajie Tang, Jiebo Luo
0
0
Text-based recommendation holds a wide range of practical applications due to its versatility, as textual descriptions can represent nearly any type of item. However, directly employing the original item descriptions may not yield optimal recommendation performance due to the lack of comprehensive information to align with user preferences. Recent advances in large language models (LLMs) have showcased their remarkable ability to harness commonsense knowledge and reasoning. In this study, we introduce a novel approach, coined LLM-Rec, which incorporates four distinct prompting strategies of text enrichment for improving personalized text-based recommendations. Our empirical experiments reveal that using LLM-augmented text significantly enhances recommendation quality. Even basic MLP (Multi-Layer Perceptron) models achieve comparable or even better results than complex content-based methods. Notably, the success of LLM-Rec lies in its prompting strategies, which effectively tap into the language model's comprehension of both general and specific item characteristics. This highlights the importance of employing diverse prompts and input augmentation techniques to boost the recommendation effectiveness of LLMs.
4/3/2024
💬
Tired of Plugins? Large Language Models Can Be End-To-End Recommenders
Wenlin Zhang, Chuhan Wu, Xiangyang Li, Yuhao Wang, Kuicai Dong, Yichao Wang, Xinyi Dai, Xiangyu Zhao, Huifeng Guo, Ruiming Tang
0
0
Recommender systems aim to predict user interest based on historical behavioral data. They are mainly designed in sequential pipelines, requiring lots of data to train different sub-systems, and are hard to scale to new domains. Recently, Large Language Models (LLMs) have demonstrated remarkable generalized capabilities, enabling a singular model to tackle diverse recommendation tasks across various scenarios. Nonetheless, existing LLM-based recommendation systems utilize LLM purely for a single task of the recommendation pipeline. Besides, these systems face challenges in presenting large-scale item sets to LLMs in natural language format, due to the constraint of input length. To address these challenges, we introduce an LLM-based end-to-end recommendation framework: UniLLMRec. Specifically, UniLLMRec integrates multi-stage tasks (e.g. recall, ranking, re-ranking) via chain-of-recommendations. To deal with large-scale items, we propose a novel strategy to structure all items into an item tree, which can be dynamically updated and effectively retrieved. UniLLMRec shows promising zero-shot results in comparison with conventional supervised models. Additionally, it boasts high efficiency, reducing the input token need by 86% compared to existing LLM-based models. Such efficiency not only accelerates task completion but also optimizes resource utilization. To facilitate model understanding and to ensure reproducibility, we have made our code publicly available.
4/9/2024
Understanding Language Modeling Paradigm Adaptations in Recommender Systems: Lessons Learned and Open Challenges
Lemei Zhang, Peng Liu, Yashar Deldjoo, Yong Zheng, Jon Atle Gulla
0
0
The emergence of Large Language Models (LLMs) has achieved tremendous success in the field of Natural Language Processing owing to diverse training paradigms that empower LLMs to effectively capture intricate linguistic patterns and semantic representations. In particular, the recent pre-train, prompt and predict training paradigm has attracted significant attention as an approach for learning generalizable models with limited labeled data. In line with this advancement, these training paradigms have recently been adapted to the recommendation domain and are seen as a promising direction in both academia and industry. This half-day tutorial aims to provide a thorough understanding of extracting and transferring knowledge from pre-trained models learned through different training paradigms to improve recommender systems from various perspectives, such as generality, sparsity, effectiveness and trustworthiness. In this tutorial, we first introduce the basic concepts and a generic architecture of the language modeling paradigm for recommendation purposes. Then, we focus on recent advancements in adapting LLM-related training strategies and optimization objectives for different recommendation tasks. After that, we will systematically introduce ethical issues in LLM-based recommender systems and discuss possible approaches to assessing and mitigating them. We will also summarize the relevant datasets, evaluation metrics, and an empirical study on the recommendation performance of training paradigms. Finally, we will conclude the tutorial with a discussion of open challenges and future directions.
4/8/2024
💬
Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, Ji-Rong Wen
0
0
Recently, large language models (LLMs) have shown great potential in recommender systems, either improving existing recommendation models or serving as the backbone. However, there exists a large semantic gap between LLMs and recommender systems, since items to be recommended are often indexed by discrete identifiers (item ID) out of the LLM's vocabulary. In essence, LLMs capture language semantics while recommender systems imply collaborative semantics, making it difficult to sufficiently leverage the model capacity of LLMs for recommendation. To address this challenge, in this paper, we propose a new LLM-based recommendation model called LC-Rec, which can better integrate language and collaborative semantics for recommender systems. Our approach can directly generate items from the entire item set for recommendation, without relying on candidate items. Specifically, we make two major contributions in our approach. For item indexing, we design a learning-based vector quantization method with uniform semantic mapping, which can assign meaningful and non-conflicting IDs (called item indices) for items. For alignment tuning, we propose a series of specially designed tuning tasks to enhance the integration of collaborative semantics in LLMs. Our fine-tuning tasks enforce LLMs to deeply integrate language and collaborative semantics (characterized by the learned item indices), so as to achieve an effective adaptation to recommender systems. Extensive experiments demonstrate the effectiveness of our method, showing that our approach can outperform a number of competitive baselines including traditional recommenders and existing LLM-based recommenders. Our code is available at https://github.com/RUCAIBox/LC-Rec/.
4/22/2024