Reasoning with fuzzy and uncertain evidence using epistemic random fuzzy sets: general framework and practical models
2202.08081
0
0
👨🏫
Abstract
We introduce a general theory of epistemic random fuzzy sets for reasoning with fuzzy or crisp evidence. This framework generalizes both the Dempster-Shafer theory of belief functions, and possibility theory. Independent epistemic random fuzzy sets are combined by the generalized product-intersection rule, which extends both Dempster's rule for combining belief functions, and the product conjunctive combination of possibility distributions. We introduce Gaussian random fuzzy numbers and their multi-dimensional extensions, Gaussian random fuzzy vectors, as practical models for quantifying uncertainty about scalar or vector quantities. Closed-form expressions for the combination, projection and vacuous extension of Gaussian random fuzzy numbers and vectors are derived.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Introduces a general theory of epistemic random fuzzy sets for reasoning with fuzzy or crisp evidence
- Generalizes the Dempster-Shafer theory of belief functions and possibility theory
- Combines independent epistemic random fuzzy sets using the generalized product-intersection rule
- Introduces Gaussian random fuzzy numbers and vectors as practical models for quantifying uncertainty
Plain English Explanation
This paper presents a new framework for reasoning with uncertain information. The researchers developed a general theory called "epistemic random fuzzy sets" that can be used to work with fuzzy or precise data. This framework builds on and extends two existing theories - the Dempster-Shafer theory of belief functions and possibility theory.
The key innovation is a new way to combine multiple sources of uncertain information, called the "generalized product-intersection rule." This rule allows the framework to handle both fuzzy and precise data, and extends the combination methods used in the Dempster-Shafer and possibility theories.
To make the framework more practical, the researchers also introduce "Gaussian random fuzzy numbers and vectors." These are statistical models that can be used to quantify uncertainty about scalar or vector quantities. The paper provides mathematical formulas for working with these Gaussian models, including how to combine them, project them onto subspaces, and handle fully uncertain or "vacuous" information.
Technical Explanation
The core contribution of this paper is a generalization of the Dempster-Shafer theory of belief functions and possibility theory into a unified framework called "epistemic random fuzzy sets." This framework allows for reasoning with both fuzzy and crisp (precise) evidence.
Independent epistemic random fuzzy sets are combined using a new "generalized product-intersection rule." This extends both Dempster's rule for combining belief functions and the product conjunctive combination of possibility distributions. The result is a more flexible way to fuse multiple sources of uncertain information.
To provide practical models within this framework, the paper introduces Gaussian random fuzzy numbers and their multi-dimensional extensions, Gaussian random fuzzy vectors. These statistical representations can be used to quantify uncertainty about scalar or vector quantities. The paper derives closed-form expressions for key operations on Gaussian random fuzzy numbers and vectors, including combination, projection, and handling of fully uncertain or "vacuous" information.
Critical Analysis
The paper presents a comprehensive theoretical framework that generalizes and unifies several important approaches to reasoning with uncertainty. By introducing the concept of epistemic random fuzzy sets and the generalized product-intersection rule, the researchers have expanded the toolbox for handling mixed fuzzy and crisp evidence.
However, the paper does not provide much guidance on how to apply this framework in practice. The mathematical formulations, while elegant, may be challenging for many readers to engage with directly. Further research is likely needed to develop more user-friendly methods and tools built on this theoretical foundation.
Additionally, the paper does not discuss the computational complexity or scalability of the proposed techniques. As the dimensionality of the problem grows, the calculations involved may become prohibitively expensive. Exploring efficient algorithms and approximation methods could be an important area for future work.
Overall, this paper makes a valuable contribution by unifying several strands of research on uncertain reasoning. The epistemic random fuzzy set framework and Gaussian models provide a rich foundation for further developments in this area. However, translating the theory into practical, scalable solutions remains an open challenge.
Conclusion
This paper presents a general theory of epistemic random fuzzy sets that provides a unified framework for reasoning with fuzzy or crisp evidence. It extends and generalizes the Dempster-Shafer theory of belief functions and possibility theory, introducing a new way to combine independent sources of uncertain information.
To make the framework more concrete, the researchers also introduce Gaussian random fuzzy numbers and vectors as statistical models for quantifying uncertainty about scalar or vector quantities. The paper provides mathematical formulas for working with these models, including combination, projection, and handling of fully uncertain or "vacuous" information.
While the theoretical contributions are significant, further research is needed to develop practical, user-friendly methods and tools based on this framework. Exploring computational efficiency and scalability will also be important to enable the application of these techniques in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Quantifying Aleatoric and Epistemic Uncertainty with Proper Scoring Rules
Paul Hofman, Yusuf Sale, Eyke Hullermeier
0
0
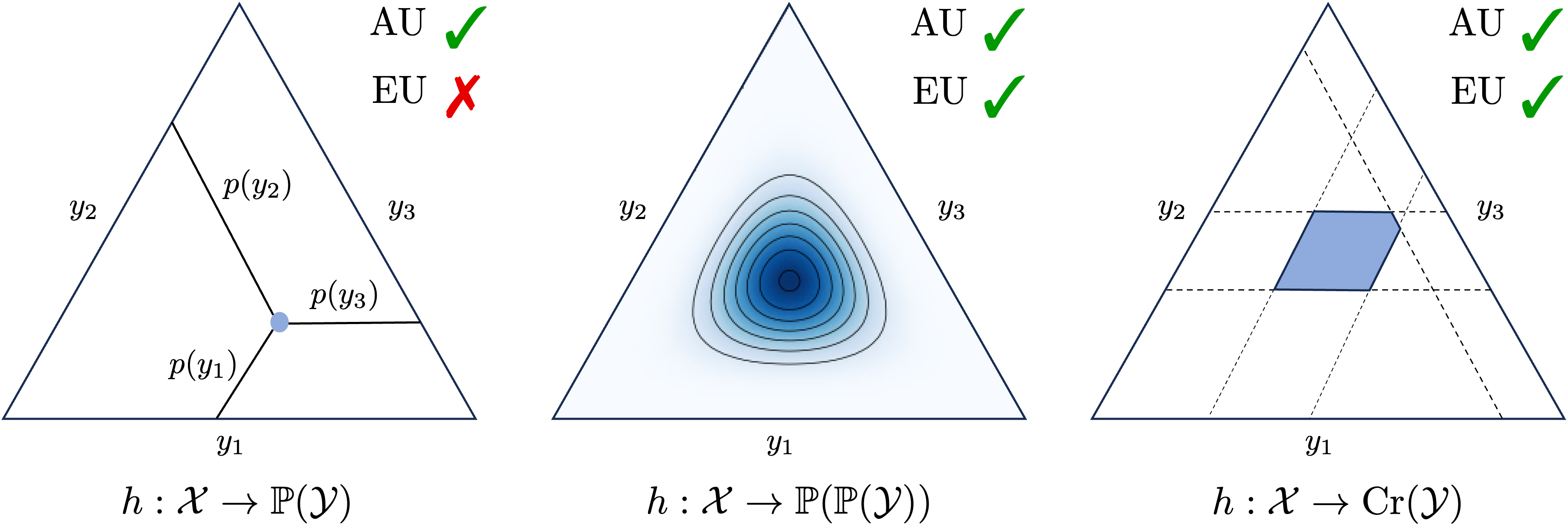
Uncertainty representation and quantification are paramount in machine learning and constitute an important prerequisite for safety-critical applications. In this paper, we propose novel measures for the quantification of aleatoric and epistemic uncertainty based on proper scoring rules, which are loss functions with the meaningful property that they incentivize the learner to predict ground-truth (conditional) probabilities. We assume two common representations of (epistemic) uncertainty, namely, in terms of a credal set, i.e. a set of probability distributions, or a second-order distribution, i.e., a distribution over probability distributions. Our framework establishes a natural bridge between these representations. We provide a formal justification of our approach and introduce new measures of epistemic and aleatoric uncertainty as concrete instantiations.
4/22/2024
Doing Experiments and Revising Rules with Natural Language and Probabilistic Reasoning
Wasu Top Piriyakulkij, Kevin Ellis
0
0
We build a computational model of how humans actively infer hidden rules by doing experiments. The basic principles behind the model is that, even if the rule is deterministic, the learner considers a broader space of fuzzy probabilistic rules, which it represents in natural language, and updates its hypotheses online after each experiment according to approximately Bayesian principles. In the same framework we also model experiment design according to information-theoretic criteria. We find that the combination of these three principles -- explicit hypotheses, probabilistic rules, and online updates -- can explain human performance on a Zendo-style task, and that removing any of these components leaves the model unable to account for the data.
5/8/2024
🌐
Generalizing Machine Learning Evaluation through the Integration of Shannon Entropy and Rough Set Theory
Olga Cherednichenko, Dmytro Chernyshov, Dmytro Sytnikov, Polina Sytnikova
0
0
This research paper delves into the innovative integration of Shannon entropy and rough set theory, presenting a novel approach to generalize the evaluation approach in machine learning. The conventional application of entropy, primarily focused on information uncertainty, is extended through its combination with rough set theory to offer a deeper insight into data's intrinsic structure and the interpretability of machine learning models. We introduce a comprehensive framework that synergizes the granularity of rough set theory with the uncertainty quantification of Shannon entropy, applied across a spectrum of machine learning algorithms. Our methodology is rigorously tested on various datasets, showcasing its capability to not only assess predictive performance but also to illuminate the underlying data complexity and model robustness. The results underscore the utility of this integrated approach in enhancing the evaluation landscape of machine learning, offering a multi-faceted perspective that balances accuracy with a profound understanding of data attributes and model dynamics. This paper contributes a groundbreaking perspective to machine learning evaluation, proposing a method that encapsulates a holistic view of model performance, thereby facilitating more informed decision-making in model selection and application.
4/22/2024
🔄
Uniform Generalization Bounds on Data-Dependent Hypothesis Sets via PAC-Bayesian Theory on Random Sets
Benjamin Dupuis, Paul Viallard, George Deligiannidis, Umut Simsekli
0
0
We propose data-dependent uniform generalization bounds by approaching the problem from a PAC-Bayesian perspective. We first apply the PAC-Bayesian framework on `random sets' in a rigorous way, where the training algorithm is assumed to output a data-dependent hypothesis set after observing the training data. This approach allows us to prove data-dependent bounds, which can be applicable in numerous contexts. To highlight the power of our approach, we consider two main applications. First, we propose a PAC-Bayesian formulation of the recently developed fractal-dimension-based generalization bounds. The derived results are shown to be tighter and they unify the existing results around one simple proof technique. Second, we prove uniform bounds over the trajectories of continuous Langevin dynamics and stochastic gradient Langevin dynamics. These results provide novel information about the generalization properties of noisy algorithms.
4/29/2024