Does GPT-4 pass the Turing test?
2310.20216
60
0
⛏️
Abstract
We evaluated GPT-4 in a public online Turing test. The best-performing GPT-4 prompt passed in 49.7% of games, outperforming ELIZA (22%) and GPT-3.5 (20%), but falling short of the baseline set by human participants (66%). Participants' decisions were based mainly on linguistic style (35%) and socioemotional traits (27%), supporting the idea that intelligence, narrowly conceived, is not sufficient to pass the Turing test. Participant knowledge about LLMs and number of games played positively correlated with accuracy in detecting AI, suggesting learning and practice as possible strategies to mitigate deception. Despite known limitations as a test of intelligence, we argue that the Turing test continues to be relevant as an assessment of naturalistic communication and deception. AI models with the ability to masquerade as humans could have widespread societal consequences, and we analyse the effectiveness of different strategies and criteria for judging humanlikeness.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers evaluated the performance of GPT-4, a large language model, in a public online Turing test.
- The best-performing GPT-4 prompt passed the test 49.7% of the time, outperforming ELIZA (22%) and GPT-3.5 (20%), but falling short of the baseline set by human participants (66%).
- Participants' decisions were based mainly on linguistic style (35%) and socioemotional traits (27%), suggesting that intelligence alone is not sufficient to pass the Turing test.
- Participant knowledge about large language models and the number of games played positively correlated with accuracy in detecting AI, indicating that learning and practice could help mitigate deception.
Plain English Explanation
Researchers wanted to see how well the GPT-4 language model could pass as a human in an online conversation. They had GPT-4 participate in an online Turing test, where people try to determine if they're talking to a human or an AI. The best GPT-4 prompt was able to fool people 49.7% of the time, which is better than the older ELIZA (22%) and GPT-3.5 (20%) models, but still not as good as real humans (66%).
The researchers found that people mainly looked at the linguistic style (how the language was used) and the emotional traits (how the "person" came across) to decide if they were talking to a human or an AI. This suggests that being intelligent or knowledgeable is not enough to fully pass as human - the AI also needs to sound and act like a person.
The study also showed that people who knew more about language models and had more experience with the test were better at spotting the AI. This means that education and practice could help people recognize when they're talking to an AI, even a very advanced one like GPT-4, and not be easily fooled.
Technical Explanation
The researchers conducted a public online Turing test to evaluate the performance of GPT-4, a state-of-the-art large language model. They collected data from 129 participants who engaged in conversational interactions with either GPT-4, ELIZA, GPT-3.5, or human participants.
The best-performing GPT-4 prompt was able to pass the Turing test 49.7% of the time, outperforming ELIZA (22%) and GPT-3.5 (20%), but falling short of the human baseline (66%). Participants' decisions were based primarily on linguistic style (35%) and socioemotional traits (27%), rather than just raw intelligence or knowledge.
The researchers found that participants' prior knowledge about large language models and the number of games played positively correlated with their ability to accurately detect AI. This suggests that learning and practice could help mitigate the deceptive capabilities of advanced AI systems.
Critical Analysis
While the Turing test has limitations as a measure of true intelligence, the researchers argue that it remains relevant for assessing naturalistic communication and deception. The ability of AI models to convincingly masquerade as humans could have significant societal consequences, underscoring the importance of this line of research.
However, the study does not address the potential biases or limitations in the participant pool or the specific criteria used to evaluate humanlikeness. Additionally, the researchers acknowledge that the Turing test may not capture the full breadth of human intelligence and communication.
Further research could explore alternative testing methodologies, expand the range of AI models evaluated, and investigate the long-term implications of increasingly sophisticated language models that can pass as human in various contexts.
Conclusion
This study provides a comparative analysis of the performance of GPT-4, a cutting-edge language model, in a public online Turing test. The results suggest that while GPT-4 can outperform previous AI systems, it still falls short of human-level performance in naturalistic communication and deception. The findings highlight the importance of considering factors beyond just intelligence, such as linguistic style and socioemotional traits, when evaluating the humanlikeness of AI systems.
The researchers emphasize the ongoing relevance of the Turing test as a tool for assessing the capabilities of advanced language models and the potential societal consequences of AI systems that can convincingly impersonate humans. This study contributes to the broader understanding of the strengths and limitations of current AI technology and the challenges of developing truly human-like communication abilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
People cannot distinguish GPT-4 from a human in a Turing test
Cameron R. Jones, Benjamin K. Bergen
0
0
We evaluated 3 systems (ELIZA, GPT-3.5 and GPT-4) in a randomized, controlled, and preregistered Turing test. Human participants had a 5 minute conversation with either a human or an AI, and judged whether or not they thought their interlocutor was human. GPT-4 was judged to be a human 54% of the time, outperforming ELIZA (22%) but lagging behind actual humans (67%). The results provide the first robust empirical demonstration that any artificial system passes an interactive 2-player Turing test. The results have implications for debates around machine intelligence and, more urgently, suggest that deception by current AI systems may go undetected. Analysis of participants' strategies and reasoning suggests that stylistic and socio-emotional factors play a larger role in passing the Turing test than traditional notions of intelligence.
5/15/2024
🧠
Comparative Analysis of ChatGPT, GPT-4, and Microsoft Bing Chatbots for GRE Test
Mohammad Abu-Haifa, Bara'a Etawi, Huthaifa Alkhatatbeh, Ayman Ababneh
0
0
This research paper presents an analysis of how well three artificial intelligence chatbots: Bing, ChatGPT, and GPT-4, perform when answering questions from standardized tests. The Graduate Record Examination is used in this paper as a case study. A total of 137 questions with different forms of quantitative reasoning and 157 questions with verbal categories were used to assess their capabilities. This paper presents the performance of each chatbot across various skills and styles tested in the exam. The proficiency of these chatbots in addressing image-based questions is also explored, and the uncertainty level of each chatbot is illustrated. The results show varying degrees of success across the chatbots, where GPT-4 served as the most proficient, especially in complex language understanding tasks and image-based questions. Results highlight the ability of these chatbots to pass the GRE with a high score, which encourages the use of these chatbots in test preparation. The results also show how important it is to ensure that, if the test is administered online, as it was during COVID, the test taker is segregated from these resources for a fair competition on higher education opportunities.
4/9/2024

How Well Can LLMs Echo Us? Evaluating AI Chatbots' Role-Play Ability with ECHO
Man Tik Ng, Hui Tung Tse, Jen-tse Huang, Jingjing Li, Wenxuan Wang, Michael R. Lyu
0
0
The role-play ability of Large Language Models (LLMs) has emerged as a popular research direction. However, existing studies focus on imitating well-known public figures or fictional characters, overlooking the potential for simulating ordinary individuals. Such an oversight limits the potential for advancements in digital human clones and non-player characters in video games. To bridge this gap, we introduce ECHO, an evaluative framework inspired by the Turing test. This framework engages the acquaintances of the target individuals to distinguish between human and machine-generated responses. Notably, our framework focuses on emulating average individuals rather than historical or fictional figures, presenting a unique advantage to apply the Turing Test. We evaluated three role-playing LLMs using ECHO, with GPT-3.5 and GPT-4 serving as foundational models, alongside the online application GPTs from OpenAI. Our results demonstrate that GPT-4 more effectively deceives human evaluators, and GPTs achieves a leading success rate of 48.3%. Furthermore, we investigated whether LLMs could discern between human-generated and machine-generated texts. While GPT-4 can identify differences, it could not determine which texts were human-produced. Our code and results of reproducing the role-playing LLMs are made publicly available via https://github.com/CUHK-ARISE/ECHO.
4/23/2024
Comparing the Efficacy of GPT-4 and Chat-GPT in Mental Health Care: A Blind Assessment of Large Language Models for Psychological Support
Birger Moell
0
0
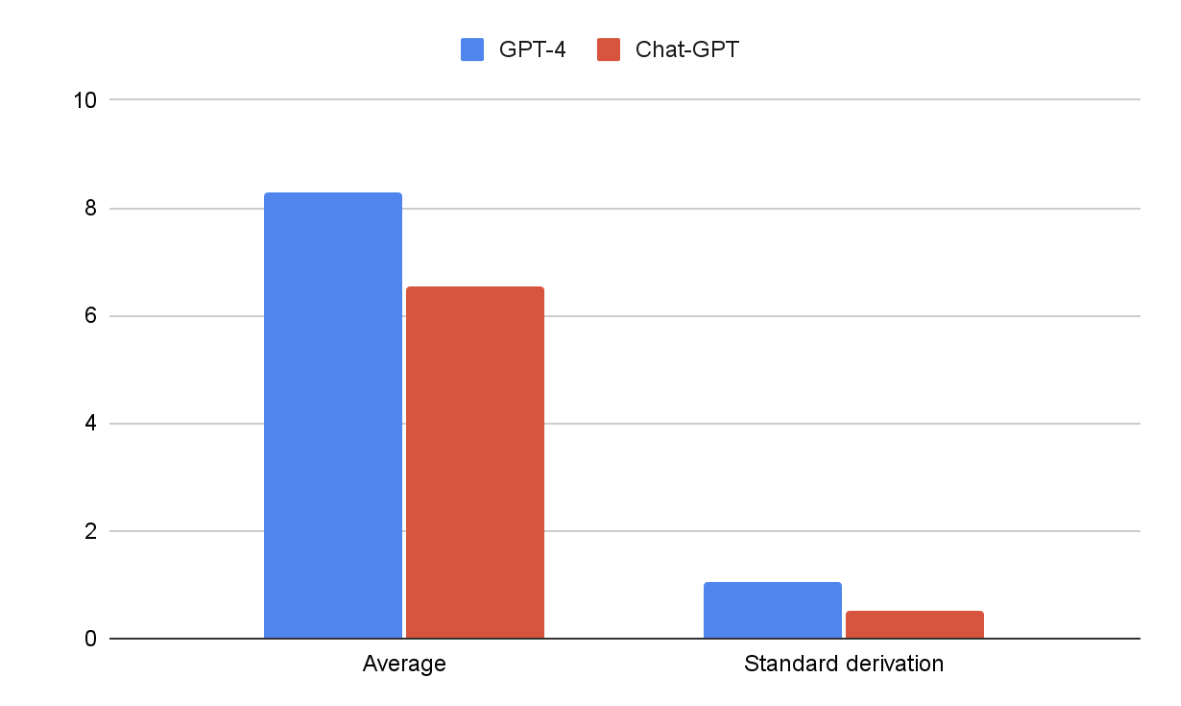
Background: Rapid advancements in natural language processing have led to the development of large language models with the potential to revolutionize mental health care. These models have shown promise in assisting clinicians and providing support to individuals experiencing various psychological challenges. Objective: This study aims to compare the performance of two large language models, GPT-4 and Chat-GPT, in responding to a set of 18 psychological prompts, to assess their potential applicability in mental health care settings. Methods: A blind methodology was employed, with a clinical psychologist evaluating the models' responses without knowledge of their origins. The prompts encompassed a diverse range of mental health topics, including depression, anxiety, and trauma, to ensure a comprehensive assessment. Results: The results demonstrated a significant difference in performance between the two models (p > 0.05). GPT-4 achieved an average rating of 8.29 out of 10, while Chat-GPT received an average rating of 6.52. The clinical psychologist's evaluation suggested that GPT-4 was more effective at generating clinically relevant and empathetic responses, thereby providing better support and guidance to potential users. Conclusions: This study contributes to the growing body of literature on the applicability of large language models in mental health care settings. The findings underscore the importance of continued research and development in the field to optimize these models for clinical use. Further investigation is necessary to understand the specific factors underlying the performance differences between the two models and to explore their generalizability across various populations and mental health conditions.
5/16/2024