AudioSetMix: Enhancing Audio-Language Datasets with LLM-Assisted Augmentations
2405.11093
0
0

Abstract
Multi-modal learning in the audio-language domain has seen significant advancements in recent years. However, audio-language learning faces challenges due to limited and lower-quality data compared to image-language tasks. Existing audio-language datasets are notably smaller, and manual labeling is hindered by the need to listen to entire audio clips for accurate labeling. Our method systematically generates audio-caption pairs by augmenting audio clips with natural language labels and corresponding audio signal processing operations. Leveraging a Large Language Model, we generate descriptions of augmented audio clips with a prompt template. This scalable method produces AudioSetMix, a high-quality training dataset for text-and-audio related models. Integration of our dataset improves models performance on benchmarks by providing diversified and better-aligned examples. Notably, our dataset addresses the absence of modifiers (adjectives and adverbs) in existing datasets. By enabling models to learn these concepts, and generating hard negative examples during training, we achieve state-of-the-art performance on multiple benchmarks.
Get summaries of the top AI research delivered straight to your inbox:
Overview
• This paper introduces AudioSetMix, a novel approach to enhance audio-language datasets using large language model (LLM)-assisted augmentations. • The key idea is to leverage LLMs to generate diverse and coherent audio mixtures, which can then be used to augment existing audio-language datasets and improve the performance of downstream models. • The researchers demonstrate the effectiveness of their approach on various audio-language tasks, including audio captioning, audio-to-text retrieval, and audio classification.
Plain English Explanation
Audio-language datasets, which contain pairs of audio recordings and associated text, are crucial for training models that can understand and process spoken language. However, these datasets are often limited in size and diversity, which can limit the performance of the models trained on them.
The researchers behind AudioSetMix have come up with a clever way to address this problem. They use large language models (LLMs), which are AI models that have been trained on vast amounts of text data, to generate new and diverse audio mixtures. These synthetic audio samples are then added to the original dataset, effectively expanding and diversifying the dataset.
The key insight is that LLMs can generate coherent and plausible audio-text pairs, which can be used to augment the existing dataset. This helps the downstream models, such as those used for audio captioning or audio-to-text retrieval, to learn more robust and generalizable representations.
The researchers show that by using AudioSetMix, they can significantly improve the performance of these models on a range of audio-language tasks. This work highlights the power of combining large language models with audio datasets to create more effective AI systems for understanding and processing spoken language.
Technical Explanation
The AudioSetMix approach involves three main steps:
-
Audio Mixture Generation: The researchers use an LLM to generate text descriptions of diverse audio mixtures, which are then used to synthesize the corresponding audio samples. This is done by leveraging CLIP, a model that can map text and audio to a shared latent space.
-
Audio-Text Pair Creation: The generated audio samples and their corresponding text descriptions are paired together to create new audio-text samples, which are then added to the original dataset.
-
Model Fine-Tuning: The researchers fine-tune various audio-language models, such as LLM-AD and AudioLDM-2, on the augmented dataset created by AudioSetMix. This leads to significant performance improvements on tasks like audio captioning, audio-to-text retrieval, and audio classification.
The researchers demonstrate the effectiveness of their approach on several benchmark datasets, including AudioSet and MACS. They show that the AudioSetMix-augmented datasets consistently outperform the original datasets, highlighting the value of leveraging LLMs for creating high-quality audio-language samples.
Critical Analysis
The AudioSetMix approach is a promising step towards enhancing audio-language datasets and improving the performance of downstream models. However, the paper does not address some potential limitations and areas for further research:
-
Authenticity of Synthetic Samples: While the generated audio-text pairs are coherent, it is unclear how authentic they are compared to real-world samples. Further evaluation of the perceptual and semantic quality of the synthetic samples would help assess their utility.
-
Generalization to Other Datasets: The research is primarily focused on the AudioSet and MACS datasets. It would be valuable to explore the performance of AudioSetMix on a wider range of audio-language datasets to assess its broader applicability.
-
Computational Complexity: The process of generating and incorporating the synthetic samples may introduce additional computational overhead, which could impact the practicality of the approach, especially for large-scale datasets. An analysis of the time and resource requirements would be beneficial.
-
Potential Biases: As with any data augmentation technique, there is a risk of introducing biases or artifacts into the dataset, which could be reflected in the downstream models. Careful monitoring and evaluation of these effects would be crucial.
Despite these potential limitations, the AudioSetMix approach represents an exciting direction in the field of audio-language understanding, leveraging the power of large language models to enhance the diversity and quality of available datasets.
Conclusion
The AudioSetMix paper introduces a novel method for enhancing audio-language datasets using LLM-assisted augmentations. By generating diverse and coherent audio mixtures and pairing them with corresponding text descriptions, the researchers demonstrate significant performance improvements on various audio-language tasks, including audio captioning, audio-to-text retrieval, and audio classification.
This work highlights the potential of combining large language models with audio datasets to create more effective AI systems for understanding and processing spoken language. As the field of audio-language understanding continues to evolve, approaches like AudioSetMix may pave the way for more robust and versatile models that can better capture the nuances and complexities of human speech and audio.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Prompting Large Language Models with Audio for General-Purpose Speech Summarization
Wonjune Kang, Deb Roy
0
0
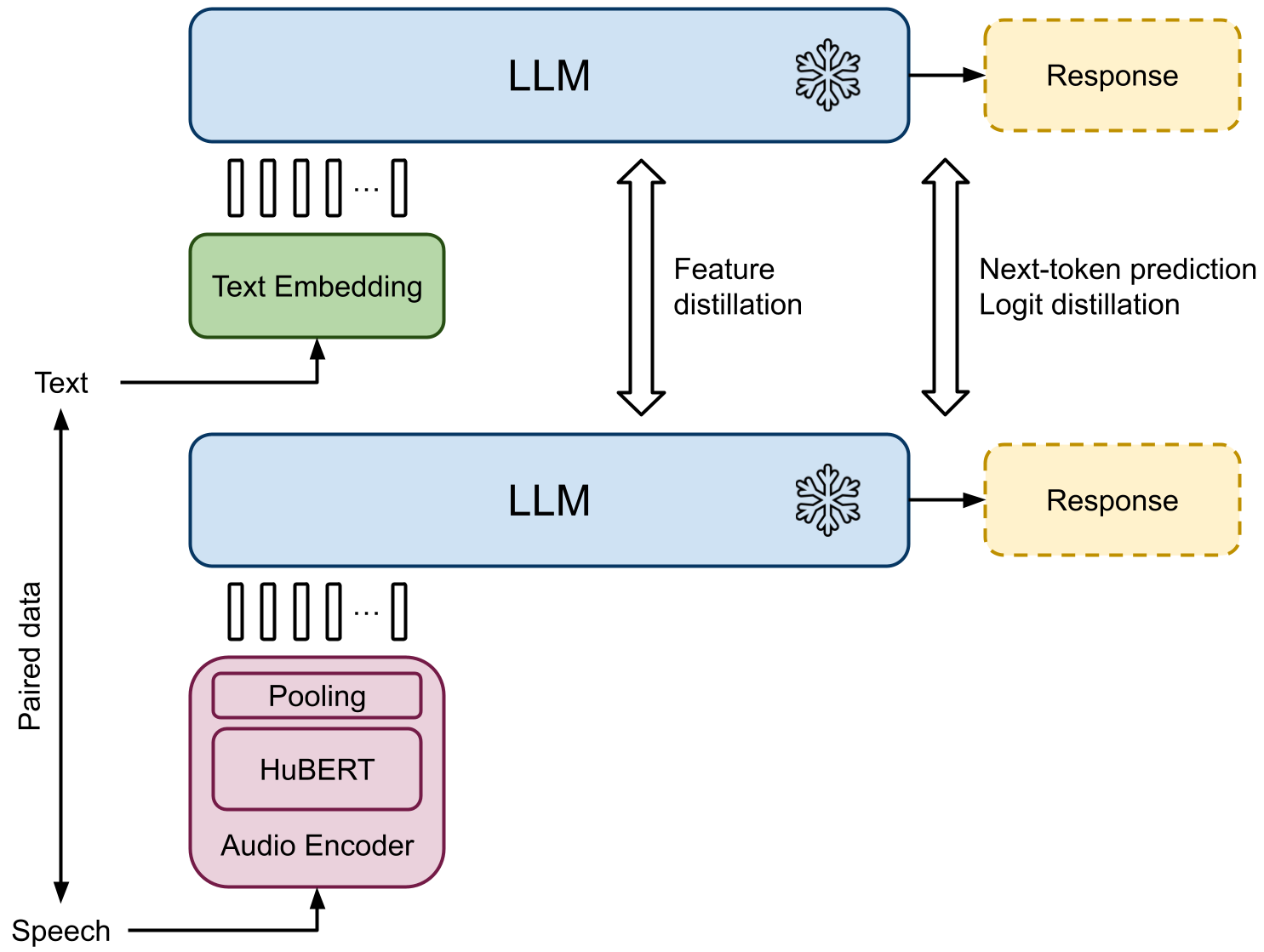
In this work, we introduce a framework for speech summarization that leverages the processing and reasoning capabilities of large language models (LLMs). We propose an end-to-end system that combines an instruction-tuned LLM with an audio encoder that converts speech into token representations that the LLM can interpret. Using a dataset with paired speech-text data, the overall system is trained to generate consistent responses to prompts with the same semantic information regardless of the input modality. The resulting framework allows the LLM to process speech inputs in the same way as text, enabling speech summarization by simply prompting the LLM. Unlike prior approaches, our method is able to summarize spoken content from any arbitrary domain, and it can produce summaries in different styles by varying the LLM prompting strategy. Experiments demonstrate that our approach outperforms a cascade baseline of speech recognition followed by LLM text processing.
6/11/2024

Bridging Language Gaps in Audio-Text Retrieval
Zhiyong Yan, Heinrich Dinkel, Yongqing Wang, Jizhong Liu, Junbo Zhang, Yujun Wang, Bin Wang
0
0
Audio-text retrieval is a challenging task, requiring the search for an audio clip or a text caption within a database. The predominant focus of existing research on English descriptions poses a limitation on the applicability of such models, given the abundance of non-English content in real-world data. To address these linguistic disparities, we propose a language enhancement (LE), using a multilingual text encoder (SONAR) to encode the text data with language-specific information. Additionally, we optimize the audio encoder through the application of consistent ensemble distillation (CED), enhancing support for variable-length audio-text retrieval. Our methodology excels in English audio-text retrieval, demonstrating state-of-the-art (SOTA) performance on commonly used datasets such as AudioCaps and Clotho. Simultaneously, the approach exhibits proficiency in retrieving content in seven other languages with only 10% of additional language-enhanced training data, yielding promising results. The source code is publicly available https://github.com/zyyan4/ml-clap.
6/12/2024
Audio Dialogues: Dialogues dataset for audio and music understanding
Arushi Goel, Zhifeng Kong, Rafael Valle, Bryan Catanzaro
0
0
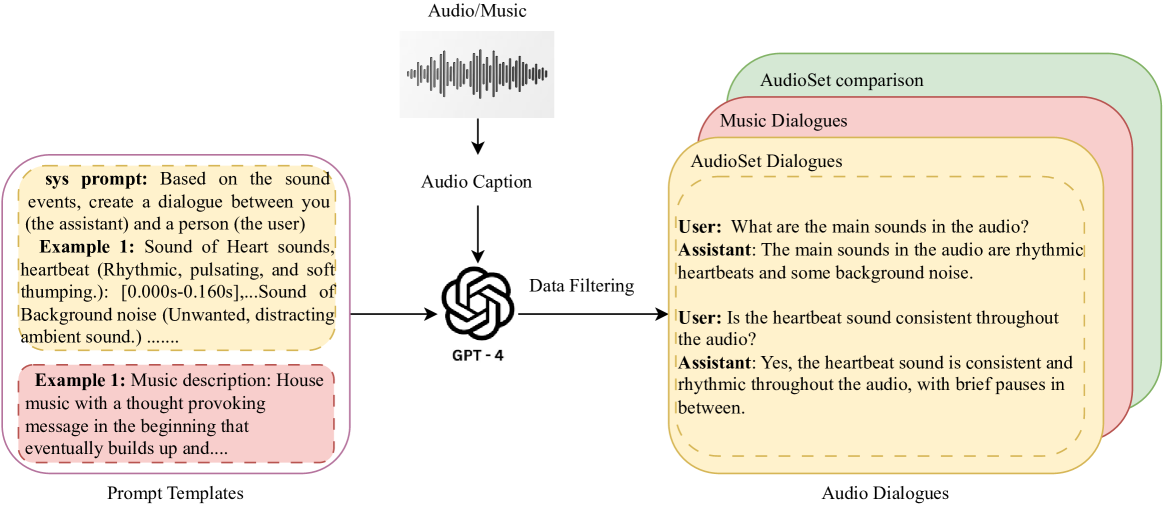
Existing datasets for audio understanding primarily focus on single-turn interactions (i.e. audio captioning, audio question answering) for describing audio in natural language, thus limiting understanding audio via interactive dialogue. To address this gap, we introduce Audio Dialogues: a multi-turn dialogue dataset containing 163.8k samples for general audio sounds and music. In addition to dialogues, Audio Dialogues also has question-answer pairs to understand and compare multiple input audios together. Audio Dialogues leverages a prompting-based approach and caption annotations from existing datasets to generate multi-turn dialogues using a Large Language Model (LLM). We evaluate existing audio-augmented large language models on our proposed dataset to demonstrate the complexity and applicability of Audio Dialogues. Our code for generating the dataset will be made publicly available. Detailed prompts and generated dialogues can be found on the demo website https://audiodialogues.github.io/.
4/12/2024

Practical aspects for the creation of an audio dataset from field recordings with optimized labeling budget with AI-assisted strategy
Javier Naranjo-Alcazar, Jordi Grau-Haro, Ruben Ribes-Serrano, Pedro Zuccarello
0
0
Machine Listening focuses on developing technologies to extract relevant information from audio signals. A critical aspect of these projects is the acquisition and labeling of contextualized data, which is inherently complex and requires specific resources and strategies. Despite the availability of some audio datasets, many are unsuitable for commercial applications. The paper emphasizes the importance of Active Learning (AL) using expert labelers over crowdsourcing, which often lacks detailed insights into dataset structures. AL is an iterative process combining human labelers and AI models to optimize the labeling budget by intelligently selecting samples for human review. This approach addresses the challenge of handling large, constantly growing datasets that exceed available computational resources and memory. The paper presents a comprehensive data-centric framework for Machine Listening projects, detailing the configuration of recording nodes, database structure, and labeling budget optimization in resource-constrained scenarios. Applied to an industrial port in Valencia, Spain, the framework successfully labeled 6540 ten-second audio samples over five months with a small team, demonstrating its effectiveness and adaptability to various resource availability situations.
5/29/2024