tortoise-tts
Maintainer: afiaka87

155
🤷
| Property | Value |
|---|---|
| Model Link | View on Replicate |
| API Spec | View on Replicate |
| Github Link | View on Github |
| Paper Link | View on Arxiv |
Get summaries of the top AI models delivered straight to your inbox:
Model overview
tortoise-tts is a text-to-speech model developed by James Betker, also known as "neonbjb". It is designed to generate highly realistic speech with strong multi-voice capabilities and natural-sounding prosody and intonation. The model is inspired by OpenAI's DALL-E and uses a combination of autoregressive and diffusion models to achieve its results.
Compared to similar models like neon-tts, tortoise-tts aims for more expressive and natural-sounding speech. It can also generate "random" voices that don't correspond to any real speaker, which can be quite fascinating to experiment with. However, the tradeoff is that tortoise-tts is relatively slow, taking several minutes to generate a single sentence on consumer hardware.
Model inputs and outputs
The tortoise-tts model takes in a text prompt and various optional parameters to control the voice and generation process. The key inputs are:
Inputs
- text: The text to be spoken
- voice_a: The primary voice to use, which can be set to "random" for a generated voice
- voice_b and voice_c: Optional secondary and tertiary voices to blend with voice_a
- preset: A set of pre-defined generation settings, such as "fast" for quicker but potentially lower-quality output
- seed: A random seed to ensure reproducible results
- cvvp_amount: A parameter to control the influence of the CVVP model, which can help reduce the likelihood of multiple speakers
The output of the model is a URI pointing to the generated audio file.
Capabilities
tortoise-tts is capable of generating highly realistic and expressive speech from text. It can mimic a wide range of voices, including those of specific speakers, and can also generate entirely new "random" voices. The model is particularly adept at capturing nuanced prosody and intonation, making the speech sound natural and lifelike.
One of the key strengths of tortoise-tts is its ability to blend multiple voices together to create a new composite voice. This allows for interesting experiments in voice synthesis and can lead to unique and unexpected results.
What can I use it for?
tortoise-tts could be useful for a variety of applications that require high-quality text-to-speech, such as audiobook production, voice-over work, or conversational AI assistants. The model's multi-voice capabilities could also be interesting for creative projects like audio drama or sound design.
However, it's important to be mindful of the ethical considerations around voice cloning technology. The maintainer, afiaka87, has addressed these concerns and implemented safeguards, such as a classifier to detect Tortoise-generated audio. Still, it's crucial to use the model responsibly and avoid any potential misuse.
Things to try
One interesting aspect of tortoise-tts is its ability to generate "random" voices that don't correspond to any real speaker. These synthetic voices can be quite captivating and may inspire creative applications or further research into generative voice synthesis.
Experimenting with the blending of multiple voices can also lead to unexpected and fascinating results. By combining different speaker characteristics, you can create unique vocal timbres and expressions.
Additionally, the model's focus on expressive prosody and intonation makes it well-suited for projects that require emotive or nuanced speech, such as audiobooks, podcasts, or interactive voice experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models

neon-tts
44
The neon-tts model is a Mycroft-compatible Text-to-Speech (TTS) plugin developed by Replicate user awerks. It utilizes the Coqui AI Text-to-Speech library to provide support for a wide range of languages, including all major European Union languages. As noted by the maintainer awerks, the model's performance is impressive, with real-time factors (RTF) ranging from 0.05 on high-end AMD/Intel machines to 0.5 on a Raspberry Pi 4. This makes the neon-tts model well-suited for a variety of applications, from desktop assistants to embedded systems. Model inputs and outputs The neon-tts model takes two inputs: a text string and a language code. The text is the input that will be converted to speech, and the language code specifies the language of the input text. The model outputs a URI representing the generated audio file. Inputs text**: The text to be converted to speech language**: The language of the input text, defaults to "en" (English) Outputs Output**: A URI representing the generated audio file Capabilities The neon-tts model is a powerful tool for generating high-quality speech from text. It supports a wide range of languages, making it useful for applications targeting international audiences. The model's impressive performance, with real-time factors as low as 0.05, allows for seamless integration into a variety of systems, from desktop assistants to embedded devices. What can I use it for? The neon-tts model can be used in a variety of applications that require text-to-speech functionality. Some potential use cases include: Virtual assistants: Integrate the neon-tts model into a virtual assistant to provide natural-sounding speech output. Accessibility tools: Use the model to convert written content to speech, making it more accessible for users with visual impairments or reading difficulties. Multimedia applications: Incorporate the neon-tts model into video, audio, or gaming applications to add voice narration or spoken dialogue. Educational resources: Create interactive learning materials that use the neon-tts model to read aloud text or provide audio instructions. Things to try One interesting aspect of the neon-tts model is its ability to support a wide range of languages, including less common ones like Irish and Maltese. This makes it a versatile tool for creating multilingual applications or content. You could experiment with generating speech in various languages to see how the model handles different linguistic structures and phonologies. Another interesting feature of the neon-tts model is its low resource requirements, allowing it to run efficiently on devices like the Raspberry Pi. This makes it a compelling choice for embedded systems or edge computing applications where performance and portability are important.
Updated Invalid Date

styletts2
100
styletts2 is a text-to-speech (TTS) model developed by Yinghao Aaron Li, Cong Han, Vinay S. Raghavan, Gavin Mischler, and Nima Mesgarani. It leverages style diffusion and adversarial training with large speech language models (SLMs) to achieve human-level TTS synthesis. Unlike its predecessor, styletts2 models styles as a latent random variable through diffusion models, allowing it to generate the most suitable style for the text without requiring reference speech. It also employs large pre-trained SLMs, such as WavLM, as discriminators with a novel differentiable duration modeling for end-to-end training, resulting in improved speech naturalness. Model inputs and outputs styletts2 takes in text and generates high-quality speech audio. The model inputs and outputs are as follows: Inputs Text**: The text to be converted to speech. Beta**: A parameter that determines the prosody of the generated speech, with lower values sampling style based on previous or reference speech and higher values sampling more from the text. Alpha**: A parameter that determines the timbre of the generated speech, with lower values sampling style based on previous or reference speech and higher values sampling more from the text. Reference**: An optional reference speech audio to copy the style from. Diffusion Steps**: The number of diffusion steps to use in the generation process, with higher values resulting in better quality but longer generation time. Embedding Scale**: A scaling factor for the text embedding, which can be used to produce more pronounced emotion in the generated speech. Outputs Audio**: The generated speech audio in the form of a URI. Capabilities styletts2 is capable of generating human-level TTS synthesis on both single-speaker and multi-speaker datasets. It surpasses human recordings on the LJSpeech dataset and matches human performance on the VCTK dataset. When trained on the LibriTTS dataset, styletts2 also outperforms previous publicly available models for zero-shot speaker adaptation. What can I use it for? styletts2 can be used for a variety of applications that require high-quality text-to-speech generation, such as audiobook production, voice assistants, language learning tools, and more. The ability to control the prosody and timbre of the generated speech, as well as the option to use reference audio, makes styletts2 a versatile tool for creating personalized and expressive speech output. Things to try One interesting aspect of styletts2 is its ability to perform zero-shot speaker adaptation on the LibriTTS dataset. This means that the model can generate speech in the style of speakers it has not been explicitly trained on, by leveraging the diverse speech synthesis offered by the diffusion model. Developers could explore the limits of this zero-shot adaptation and experiment with fine-tuning the model on new speakers to further improve the quality and diversity of the generated speech.
Updated Invalid Date
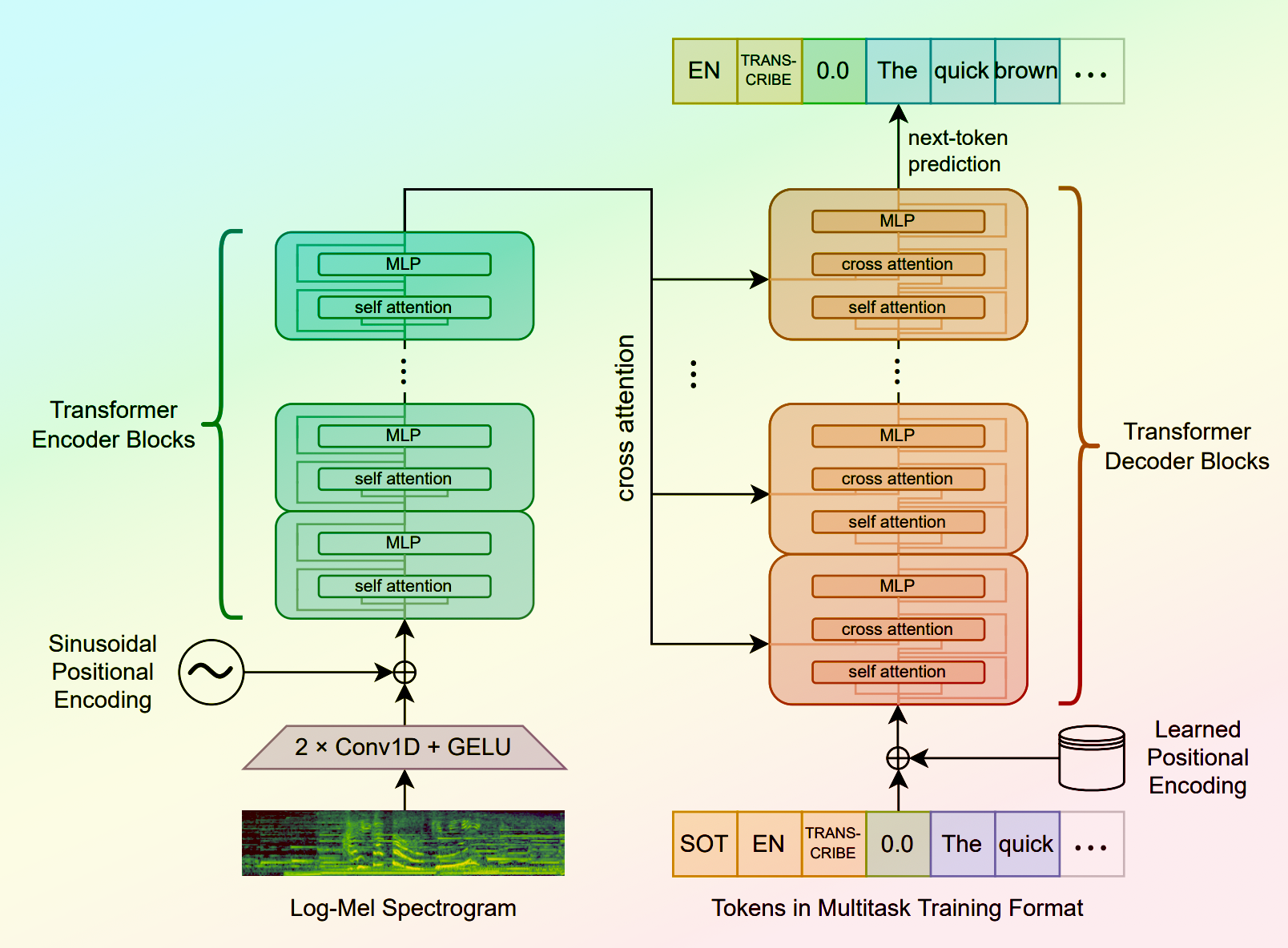
whisper
7.0K
Whisper is a general-purpose speech recognition model developed by OpenAI. It is capable of converting speech in audio to text, with the ability to translate the text to English if desired. Whisper is based on a large Transformer model trained on a diverse dataset of multilingual and multitask speech recognition data. This allows the model to handle a wide range of accents, background noises, and languages. Similar models like whisper-large-v3, incredibly-fast-whisper, and whisper-diarization offer various optimizations and additional features built on top of the core Whisper model. Model inputs and outputs Whisper takes an audio file as input and outputs a text transcription. The model can also translate the transcription to English if desired. The input audio can be in various formats, and the model supports a range of parameters to fine-tune the transcription, such as temperature, patience, and language. Inputs Audio**: The audio file to be transcribed Model**: The specific version of the Whisper model to use, currently only large-v3 is supported Language**: The language spoken in the audio, or None to perform language detection Translate**: A boolean flag to translate the transcription to English Transcription**: The format for the transcription output, such as "plain text" Initial Prompt**: An optional initial text prompt to provide to the model Suppress Tokens**: A list of token IDs to suppress during sampling Logprob Threshold**: The minimum average log probability threshold for a successful transcription No Speech Threshold**: The threshold for considering a segment as silence Condition on Previous Text**: Whether to provide the previous output as a prompt for the next window Compression Ratio Threshold**: The maximum compression ratio threshold for a successful transcription Temperature Increment on Fallback**: The temperature increase when the decoding fails to meet the specified thresholds Outputs Transcription**: The text transcription of the input audio Language**: The detected language of the audio (if language input is None) Tokens**: The token IDs corresponding to the transcription Timestamp**: The start and end timestamps for each word in the transcription Confidence**: The confidence score for each word in the transcription Capabilities Whisper is a powerful speech recognition model that can handle a wide range of accents, background noises, and languages. The model is capable of accurately transcribing audio and optionally translating the transcription to English. This makes Whisper useful for a variety of applications, such as real-time captioning, meeting transcription, and audio-to-text conversion. What can I use it for? Whisper can be used in various applications that require speech-to-text conversion, such as: Captioning and Subtitling**: Automatically generate captions or subtitles for videos, improving accessibility for viewers. Meeting Transcription**: Transcribe audio recordings of meetings, interviews, or conferences for easy review and sharing. Podcast Transcription**: Convert audio podcasts to text, making the content more searchable and accessible. Language Translation**: Transcribe audio in one language and translate the text to another, enabling cross-language communication. Voice Interfaces**: Integrate Whisper into voice-controlled applications, such as virtual assistants or smart home devices. Things to try One interesting aspect of Whisper is its ability to handle a wide range of languages and accents. You can experiment with the model's performance on audio samples in different languages or with various background noises to see how it handles different real-world scenarios. Additionally, you can explore the impact of the different input parameters, such as temperature, patience, and language detection, on the transcription quality and accuracy.
Updated Invalid Date
🧪
tortoise-tts-v2
188
The tortoise-tts-v2 is a text-to-speech AI model that can generate speech from text. Similar models include styletts2 for generating speech, xtts-v2 for multilingual text-to-speech voice cloning, parakeet-rnnt-1.1b for high-accuracy speech-to-text conversion, and voicecraft for zero-shot speech editing and text-to-speech. Model inputs and outputs The tortoise-tts-v2 model takes text as input and generates corresponding speech audio as output. Inputs Text prompts to be converted to speech Outputs Audio files containing the generated speech Capabilities The tortoise-tts-v2 model can generate high-quality speech from text input. It aims to produce natural-sounding audio with accurate pronunciation and inflection. What can I use it for? The tortoise-tts-v2 model could be used to add text-to-speech functionality to various applications, such as educational resources, audiobooks, virtual assistants, or text-to-speech conversion tools. By leveraging the model's capabilities, developers can create more accessible and engaging user experiences. Things to try Experimenting with different text prompts and evaluating the quality of the generated speech could provide insights into the model's strengths and limitations. Trying the model with various languages, accents, or specialized vocabulary could also reveal its versatility and robustness.
Updated Invalid Date